convert_images_s3
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
convert_images_s3 = dataflows.import_module("convert_images_s3", "elijahbenizzy")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(convert_images_s3)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[convert_images_s3.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.elijahbenizzy import convert_images_s3
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(convert_images_s3)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[convert_images_s3.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(convert_images_s3, "path/to/save/to")
Purpose of this module
This module allows you to convert a variety of images in S3, placing them next to the originals.
It handles anything that pillow can handle.
Configuration Options
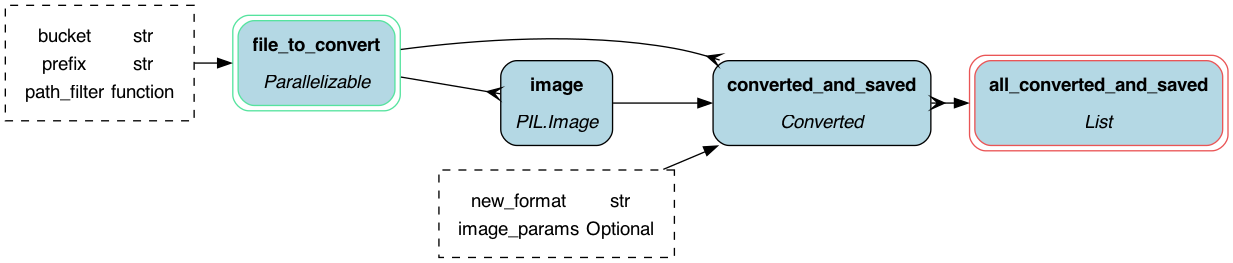
This modules takes in no configuration options. It does take in the following parameters as inputs:
path_filter-- a lambda function to take in a path and returnTrueif you want to convert it andFalseotherwise. This defaults to checking if the path extension is.png.prefix-- a prefix inside the bucket to look for images.bucket-- the bucket to look for images in.new_format-- the format to convert the images to.image_params-- a dictionary of parameters to pass to theImage.savefunction. This defaults toNone, which gets read as an empty dictionary.
Limitations
Assumes:
- The files are labeled by extension correctly
- They are all in the same format
Source code
__init__.py
import dataclasses
import functools
import io
import logging
from types import FunctionType
from typing import Any, Dict, List, Optional
from hamilton.htypes import Collect, Parallelizable
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import boto3
from PIL import Image
DEFAULT_AWS_PROFILE = "default"
@functools.lru_cache
def _s3() -> boto3.resource:
"""Returns a boto3 resource for the 'aws_profile' profile.
This allows us to bypass any serialization concerns using parallelism."""
return boto3.resource("s3")
@dataclasses.dataclass
class ToConvert:
"""Simple dataclass to contain downloading files"""
key: str
bucket: str
current_format: str
@dataclasses.dataclass
class Converted:
"""Simple dataclass to contain downloading files"""
key: str
bucket: str
new_format: str
def file_to_convert(
bucket: str,
prefix: str,
path_filter: FunctionType = lambda x: x.endswith("png"),
) -> Parallelizable[ToConvert]:
"""Returns a list of all files to convert."""
# TODO -- list bucket out
s3_resource = _s3()
bucket_obj = s3_resource.Bucket(bucket)
for item in list(bucket_obj.objects.filter(Prefix=prefix).all()):
if path_filter(item.key):
yield ToConvert(
key=item.key,
bucket=bucket,
current_format=item.key.split(".")[-1],
)
def image(file_to_convert: ToConvert) -> Image:
"""Returns a list of all files to convert."""
# TODO -- list bucket out
s3 = _s3()
bucket = s3.Bucket(file_to_convert.bucket)
obj = bucket.Object(file_to_convert.key)
stream = obj.get()["Body"]
return Image.open(stream)
def converted_and_saved(
image: Image,
file_to_convert: ToConvert,
new_format: str = "jpeg",
image_params: Optional[Dict[str, Any]] = None,
) -> Converted:
"""Returns a list of all files to convert."""
s3 = _s3()
if image_params is None:
image_params = {}
in_mem_file = io.BytesIO()
try:
if new_format in ("jpeg", "jpg"): # TODO -- add more formats if they don't support it
if image.mode in ("RGBA", "P"):
image = image.convert("RGB")
image.save(in_mem_file, format=new_format, **image_params)
except Exception as e:
logger.error(f"Failed to convert {file_to_convert.key} to {new_format} due to {e}")
raise e
in_mem_file.seek(0)
new_key = file_to_convert.key.replace(f".{file_to_convert.current_format}", f".{new_format}")
s3_object = s3.Object(file_to_convert.bucket, new_key)
# Upload the file
s3_object.put(Body=in_mem_file)
logger.info(f"Converted {file_to_convert.key} to {new_format} and saved to {new_key}")
return Converted(
key=new_key,
bucket=file_to_convert.bucket,
new_format=new_format,
)
def all_converted_and_saved(converted_and_saved: Collect[Converted]) -> List[Converted]:
"""Returns a list of all downloaded locations"""
return list(converted_and_saved)
if __name__ == "__main__":
import __init__ as convert_images
from hamilton import base, driver
dr = driver.Driver(
{},
convert_images,
adapter=base.DefaultAdapter(),
)
# saves to current working directory creating dag.png.
dr.display_all_functions("dag", {"format": "png", "view": False}, show_legend=False)
Requirements
boto3
pillow