caption_images
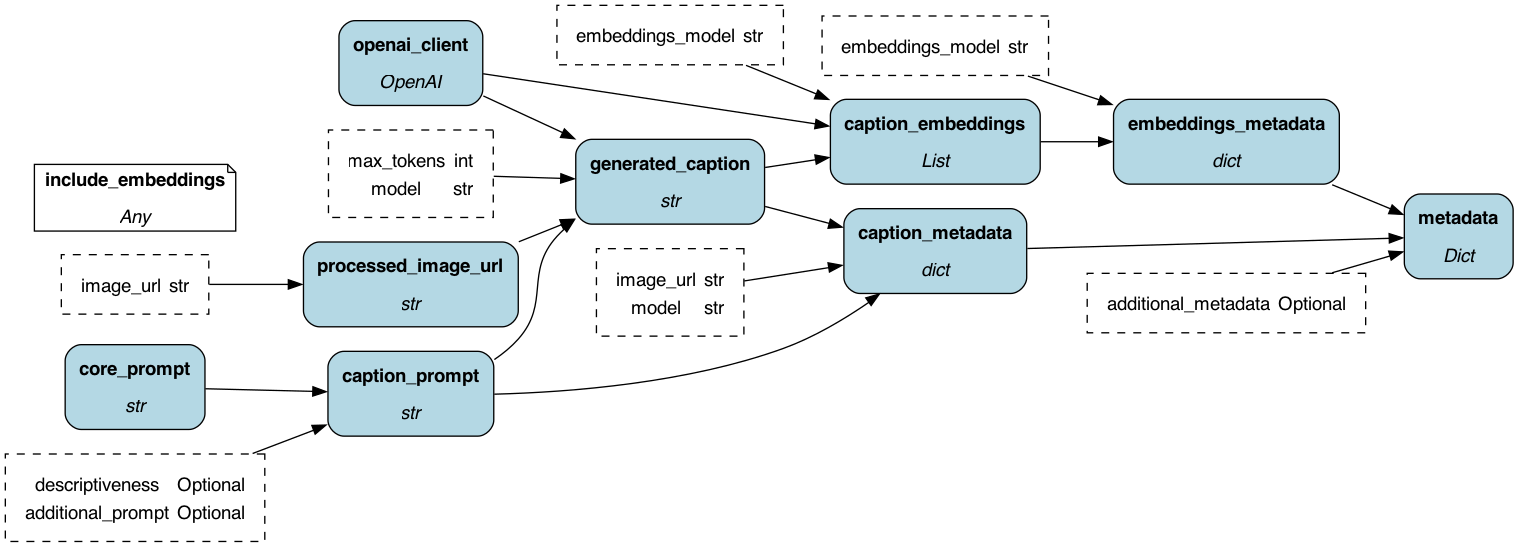
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
caption_images = dataflows.import_module("caption_images", "elijahbenizzy")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(caption_images)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[caption_images.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.elijahbenizzy import caption_images
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(caption_images)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[caption_images.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(caption_images, "path/to/save/to")
Purpose of this module
This module provides a simple dataflow to provide a caption for images using openai.
Configuration Options
This module has the following configuration options:
include_embeddings={True, False}-- whether to include embeddings in the output. Defaults toFalse
This module can be called with the following inputs, when include_embeddings=False:
image_urlThe url of the image to caption (can be locally stored or remotely stored). If locally stored, this will be encoded in base64. If remotely store,d the URL will be sent to openAI (so it has to be publicly accessible)additional_promptOptional, defaults toNone. This is an additional prompt that will be added to the end of the prompt. Examples include:- "Please make this caption overly dramatic and comical"
- "Please make this caption very concise"
descriptivenessOne of [None, "somewhat", "very", "extremely", "obsessively"], used to create the prompt.- If None, the prompt will be "Please provide a caption of the following image"
- If provided, the prompt will be "Please provide a caption of the following image. The caption should be {descriptiveness} descriptive"
max_tokensMax number of tokens to use for openAIadditional_metadataOptional, defaults toNone. If provided, this will be added to the metadata dict returned at the end.
In addition, this module can be called with the following inputs, when include_embeddings=True:
embeddings_modelOptional, defaults to "text-embeddings-ada-002", if caption_embeddings is on the blocking path
Note that you must have OPENAI_API_KEY set in your environment for this to work.
This also accepts the following overrides:
core_promptThe prompt to use, overrides the default prompt or "Please provide a caption for this image"
Note that this has two modes:
- (
include_embeddings=False, or not specified) Just quries the caption for the image. You can requestgenerated_caption, which will give embeddings for the caption. - (
include_embeddings=True): also gets the caption for the image, and the embeddings the caption. This requirescaption_embeddingsto be one of the variables called.
If you want all the metadata about this run wrapped up in a dictionary (say, to save externally), you can request metadata which will return a dict with the following keys:
When include_embeddings=False:
original_image_url: original, provide image URL -- if this has been converted to base64 this will be the original pathgenerated_caption: caption generated by the captioning modelcaption_model: the model used to generate the captioncaption_prompt: the prompt used to generate the caption**additional_metadata: any additional metadata passed inexecution_time: current time when this is generated, in ISO format
If include_embeddings=True, you will get the above, as well as:
caption_embeddings: embeddings for the captionembeddings_model: the model used to generate the embeddings
Limitations
We may consider breaking this into multiple DAGs at some point, as it does two separate pieces. For now, however, it has some basic capabilities.
Source code
__init__.py
import base64
import datetime
import logging
from typing import IO, Any, Dict, List, Optional, Union
from hamilton.function_modifiers import config
logger = logging.getLogger(__name__)
import urllib
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
# non-hamilton imports go here
import boto3
import openai
def openai_client() -> openai.OpenAI:
"""OpenAI client to use"""
return openai.OpenAI()
def _encode_image(image_path_or_file: Union[str, IO], ext: str):
"""Helper fn to return a base-64 encoded image"""
file_like_object = (
image_path_or_file
if hasattr(image_path_or_file, "read")
else open(image_path_or_file, "rb")
)
with file_like_object as image_file:
out = base64.b64encode(image_file.read()).decode("utf-8")
return f"data:image/{ext};base64,{out}"
def core_prompt() -> str:
"""This is the core prompt. You can override this if needed."""
return "Please provide a caption for this image."
def processed_image_url(image_url: str) -> str:
"""Returns a processed image URL -- base-64 encoded if it is local,
otherwise remote if it is a URL"""
is_local = urllib.parse.urlparse(image_url).scheme == ""
is_s3 = urllib.parse.urlparse(image_url).scheme == "s3"
ext = image_url.split(".")[-1]
if is_local:
# In this case we load up/encode
return _encode_image(image_url, ext)
elif is_s3:
# In this case we just return the URL
client = boto3.client("s3")
bucket = urllib.parse.urlparse(image_url).netloc
key = urllib.parse.urlparse(image_url).path[1:]
obj = client.get_object(Bucket=bucket, Key=key)
return _encode_image(obj["Body"], ext)
# In this case we just return the URL
return image_url
def caption_prompt(
core_prompt: str,
additional_prompt: Optional[str] = None,
descriptiveness: Optional[str] = None,
) -> str:
"""Returns the prompt used to describe an image"""
out = core_prompt
if descriptiveness is not None:
out += f" The caption should be {descriptiveness} descriptive."
if additional_prompt is not None:
out += f" {additional_prompt}"
return out
DEFAULT_MODEL = "gpt-4-vision-preview"
DEFAULT_EMBEDDINGS_MODEL = "text-embedding-ada-002"
def generated_caption(
processed_image_url: str,
caption_prompt: str,
openai_client: openai.OpenAI,
model: str = DEFAULT_MODEL,
max_tokens: int = 2000,
) -> str:
"""Returns the response to a given chat"""
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": caption_prompt,
},
{"type": "image_url", "image_url": {"url": f"{processed_image_url}"}},
],
}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
)
return response.choices[0].message.content
@config.when(include_embeddings=True)
def caption_embeddings(
openai_client: openai.OpenAI,
embeddings_model: str = DEFAULT_EMBEDDINGS_MODEL,
generated_caption: str = None,
) -> List[float]:
"""Returns the embeddings for a generated caption"""
data = (
openai_client.embeddings.create(
input=[generated_caption],
model=embeddings_model,
)
.data[0]
.embedding
)
return data
def caption_metadata(
image_url: str,
generated_caption: str,
caption_prompt: str,
model: str = DEFAULT_MODEL,
) -> dict:
"""Returns metadata for the caption portion of the workflow"""
return {
"original_image_url": image_url,
"generated_caption": generated_caption,
"caption_model": model,
"caption_prompt": caption_prompt,
}
@config.when(include_embeddings=True)
def embeddings_metadata(
caption_embeddings: List[float],
embeddings_model: str = DEFAULT_EMBEDDINGS_MODEL,
) -> dict:
"""Returns metadata for the embeddings portion of the workflow"""
return {
"caption_embeddings": caption_embeddings,
"embeddings_model": embeddings_model,
}
def metadata(
embeddings_metadata: dict,
caption_metadata: Optional[dict] = None,
additional_metadata: Optional[dict] = None,
) -> Dict[str, Any]:
"""Returns the response to a given chat"""
out = embeddings_metadata
if caption_metadata is not None:
out.update(caption_metadata)
if additional_metadata is not None:
out.update(additional_metadata)
out.update({"execution_time": datetime.datetime.utcnow().isoformat()})
return out
if __name__ == "__main__":
# Code to create an imaging showing on DAG workflow.
# run as a script to test Hamilton's execution
import __init__ as image_captioning
from hamilton import base, driver
dr = driver.Driver(
{"include_embeddings": True}, # CONFIG: fill as appropriate
image_captioning,
adapter=base.DefaultAdapter(),
)
# saves to current working directory creating dag.png.
dr.display_all_functions("dag", {"format": "png", "view": False}, show_legend=False)
Requirements
boto3
# put non-hamilton requirements here
openai