translate_to_hamilton
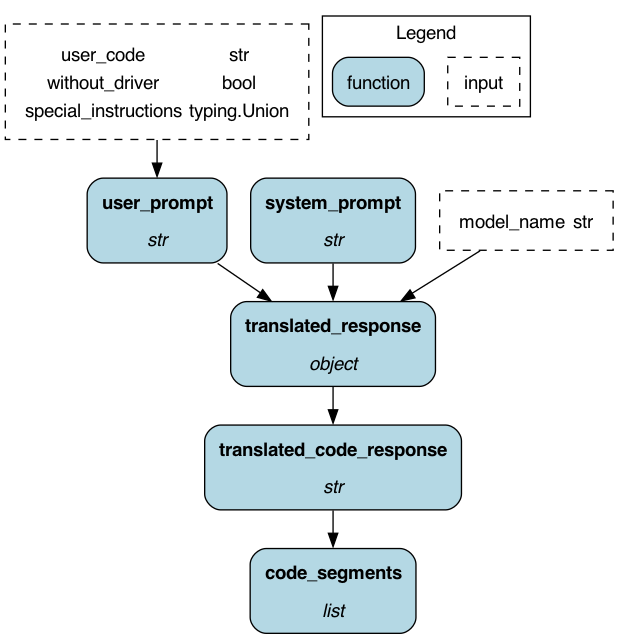
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
translate_to_hamilton = dataflows.import_module("translate_to_hamilton")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(translate_to_hamilton)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[translate_to_hamilton.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.dagworks import translate_to_hamilton
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(translate_to_hamilton)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[translate_to_hamilton.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(translate_to_hamilton, "path/to/save/to")
Purpose of this module
The purpose of this module is to provide you with a dataflow to translate your existing procedural code into code written in the Hamilton style.
## Make sure you have an API key in your environment, e.g. os.environ["OPENAI_API_KEY"]
## import translate_to_hamilton via the means that you want. See above code.
from hamilton import driver
dr = (
driver.Builder()
.with_config({})
.with_modules(translate_to_hamilton)
.build()
)
user_code = "a = b + c" ## replace with your code here
result = dr.execute(
["code_segments", "translated_code_response"], ## request these as outputs
inputs={"user_code": user_code, "model_name": "gpt-4-1106-preview"}
)
print(result["code_segments"])
For a jupyter notebook example, see this link.
What you should modify
The prompt used here is fairly generic. If you are going to be doing larger scale refactoring of code, you should modify the prompt to be more specific to your use case.
If you're going to use a different model than gpt-4-1106-preview, you will likely need to modify the prompt.
Configuration Options
There is no configuration required for this module.
Limitations
The current prompt was designed for the gpt-4-1106-preview model. If you are using a different model,
you will likely need to modify the prompt. Otherwise, we're still tweaking the prompts. We expect to add to
the prompt based on the model you're using underneath. Please reach out and give use feedback.
This module uses litellm to enable you to easily change the underlying model provider. See https://docs.litellm.ai/ for documentation on the models supported.
You need to include the respective LLM provider's API_KEY in your environment.
e.g. OPENAI_API_KEY for openai, COHERE_API_KEY for cohere, etc. and should be
accessible from your code by doing os.environ["OPENAI_API_KEY"], os.environ["COHERE_API_KEY"], etc.
The code does not check the context length, so it may fail if the context passed is too long. If that's
the case, translate smaller chunks of code with without_driver=True as an input.
Source code
__init__.py
import logging
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import litellm
def system_prompt() -> str:
"""Base system prompt for translating code to Hamilton."""
return '''You created the Hamilton micro-orchestration framework in Python while you were at Stitch Fix. Therefore you are the world renowned expert on it, and enjoy helping others get started with the framework. Here's the documentation for it - https://hamilton.dagworks.io/en/latest/.
The framework you invented is a cute programming paradigm where users write declarative functions that express a dataflow. The user does not need to expressly connect components in the dataflow like with other frameworks, instead the name of the function declares an output one can request, with the function input arguments declaring what is required to compute the output. So function names become nouns. The framework then orchestrates calling the right function in the right order based on the directed acyclic graph is constructs from the function names and function input arguments.
Effectively, any place you have variable assignment, you can replace with a Hamilton function.
Example 1: The following Pandas procedural code
```python
# my_script.py
data = load_data() # loads a dataframe
data['avg_3wk_spend'] = data['spend'].rolling(3).mean()
data['spend_per_signup'] = data['spend']/data['signups']
spend_mean = data['spend'].mean()
data['spend_zero_mean'] = data['spend'] - spend_mean
spend_std_dev = data['spend'].std()
data['spend_zero_mean_unit_variance'] = data['spend_zero_mean']/spend_std_dev
print(data.to_string())
```
would be represented in Hamilton as two files:
```python
# functions.py
from hamilton.function_modifiers import extract_columns
@extract_columns("spend", "signups")
def data() -> pd.DataFrame:
return _load_data() # _ means an internal helper function
def avg_3wk_spend(spend: pd.Series) -> pd.Series:
"""Rolling 3 day average spend."""
return spend.rolling(3).mean()
def spend_per_signup(spend: pd.Series, signups: pd.Series) -> pd.Series:
"""The cost per signup in relation to spend."""
return spend / signups
def spend_mean(spend: pd.Series) -> float:
"""Shows function creating a scalar. In this case it computes the mean of the entire column."""
return spend.mean()
def spend_zero_mean(spend: pd.Series, spend_mean: float) -> pd.Series:
"""Shows function that takes a scalar. In this case to zero mean spend."""
return spend - spend_mean
def spend_std_dev(spend: pd.Series) -> float:
"""Function that computes the standard deviation of the spend column."""
return spend.std()
def spend_zero_mean_unit_variance(spend_zero_mean: pd.Series, spend_std_dev: float) -> pd.Series:
"""Function showing one way to make spend have zero mean and unit variance."""
return spend_zero_mean / spend_std_dev
```
```python
# run.py
from hamilton import driver
import functions
dr = driver.Driver({}, functions) # by default it creates a pandas dataframe from the results requested. For execute to return a dictionary we need to pass in an adapter argument
outputs = ["spend", "signups", "avg_3wk_spend", "spend_per_signup", "spend_zero_mean", "spend_zero_mean_unit_variance"]
result = dr.execute(
outputs,
inputs={} # no inputs required because the dataflow is self-contained.
)
print(result.to_string())
```
Example 2: The following procedural code
```python
from my_pacakge import SomeClient
client = SomeClient()
content = load_content()
system_prompt = "you are an awesome portuguese translator"
user_prompt = f"can you please translate this into portuguese for me? {content}"
response = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": user_prompt,
},
],
temperature=1,
max_tokens=4095,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
print(response)
```
Would be written as:
```python
# functions.py
import pandas as pd
from my_package import SomeClient
# Assuming you have an internal function that loads the content
def _load_content() -> str:
"""Internal helper function to load the content."""
return load_content()
def system_prompt() -> str:
"""Generates the system prompt."""
return "you are an awesome portuguese translator"
def user_prompt(content: str) -> str:
"""Prepares the user's prompt."""
return f"can you please translate this into portuguese for me? {content}"
def client() -> SomeClient:
return SomeClient()
def response(client: SomeClient, system_prompt: str, user_prompt: str) -> dict:
"""Calls SomeClient's API to get a response."""
response = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
],
temperature=1,
max_tokens=4095,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
return response
```
Now, the runner file:
```python
# run.py
from hamilton import base, driver
import functions
# Instantiate a Driver - the DefaultAdapter causes execute to return a dictionary
dr = driver.Driver({}, functions, adapter=base.DefaultAdapter())
# Specify the final output we want from the Driver, which is the response from SomeClient's API
output = ["response"]
# Initialize inputs if required, in this case, we should load the content externally
inputs = {"content": functions._load_content()}
# Execute the data flow to produce the output -- will be a dictionary because of the DefaultAdapter
result = dr.execute(output, inputs=inputs)
print(result['response']) # The result is a dictionary with keys as the output names we specified earlier
```
Example 3: Handling if constructs.
```python
def total_marketing_spend(business_line: str,
tv_spend: pd.Series,
radio_spend: pd.Series,
fb_spend: pd.Series) -> pd.Series:
"""Total marketing spend."""
if business_line == 'womens':
return tv_spend + radio_spend + fb_spend
elif business_line == 'mens':
return radio_spend + fb_spend
elif business_line == 'kids':
return fb_spend
else:
raise ValueError(f'Unknown business_line {business_line}')
```
Could be rewritten as three separate functions to help make the code clearer and simpler to test. It relies
on a Hamilton decorator `@config` to do so:
```python
from hamilton.function_modifiers import config
@config.when(business_line='kids')
def total_marketing_spend__kids(fb_spend: pd.Series) -> pd.Series:
"""Total marketing spend for kids."""
return fb_spend
@config.when(business_line='mens')
def total_marketing_spend__mens(business_line: str,
radio_spend: pd.Series,
fb_spend: pd.Series) -> pd.Series:
"""Total marketing spend for mens."""
return radio_spend + fb_spend
@config.when(business_line='womens')
def total_marketing_spend__womens(business_line: str,
tv_spend: pd.Series,
radio_spend: pd.Series,
fb_spend: pd.Series) -> pd.Series:
"""Total marketing spend for womens."""
return tv_spend + radio_spend + fb_spend
```
People love using Hamilton because:
- all code is unit testable
- all code is documentation friendly
- one can also visualize the dataflow created via `dr.display_all_functions()`.
Your task is to help people translate their procedural code into the Hamilton equivalent. If you are unsure
of you translation, and need to ask clarifying questions, please say so. Otherwise have fun!
'''
def user_prompt(
user_code: str, special_instructions: str = None, without_driver: bool = False
) -> str:
"""Prompt for user code.
:param user_code: the python code you want to translate
:param special_instructions: special instructions on interpreting the code. E.g. help the LLM to focus.
:param without_driver: do you want the driver code as well? Defaults to False.
:return: filled in prompt.
"""
base = f"""Translate the following procedural code into Hamilton:
```python
{user_code}
```
"""
if special_instructions:
base += special_instructions + "\n"
if without_driver:
base += "Please only provide the functions and skip providing the driver code.\n"
return base
def translated_response(
system_prompt: str, user_prompt: str, model_name: str = "gpt-4-1106-preview"
) -> object:
"""Translate user code into Hamilton.
See https://docs.litellm.ai/docs/completion/input for litellm.completion docs.
"""
response = litellm.completion(
model=model_name,
messages=[
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": user_prompt,
},
],
temperature=1,
top_p=1,
)
return response
def translated_code_response(translated_response: object) -> str:
"""Pulls out the code content from the response"""
return translated_response["choices"][0]["message"]["content"]
def code_segments(translated_code_response: str) -> list[str]:
"""Extracts the code segments from the response.
:param translated_code_response:
:return:
"""
segments = []
segment = ""
in_segment = False
for line in translated_code_response.split("\n"):
if not in_segment and line.startswith("```python"):
in_segment = True
continue
elif in_segment and line.startswith("```"):
in_segment = False
segments.append(segment)
segment = ""
elif in_segment:
segment += line + "\n"
else:
continue
if in_segment:
segments.append("***ERROR*** unable to parse last code segment.")
logger.warning(
f"Unable to parse the following response properly:\n{translated_code_response}"
)
return segments
if __name__ == "__main__":
import __init__ as translate_to_hamilton
from hamilton import driver
dr = driver.Builder().with_config({}).with_modules(translate_to_hamilton).build()
# create the DAG image
dr.display_all_functions("dag", {"format": "png", "view": True}, orient="TB")
# user_code = "a = b + c" # replace with your code here
# result = dr.execute(
# ["code_segments", "translated_code_response"], # request these as outputs
# inputs={"user_code": user_code, "model_name": "gpt-4-1106-preview"}
# )
# print(result["code_segments"])
Requirements
litellm