sphinx_doc_chunking
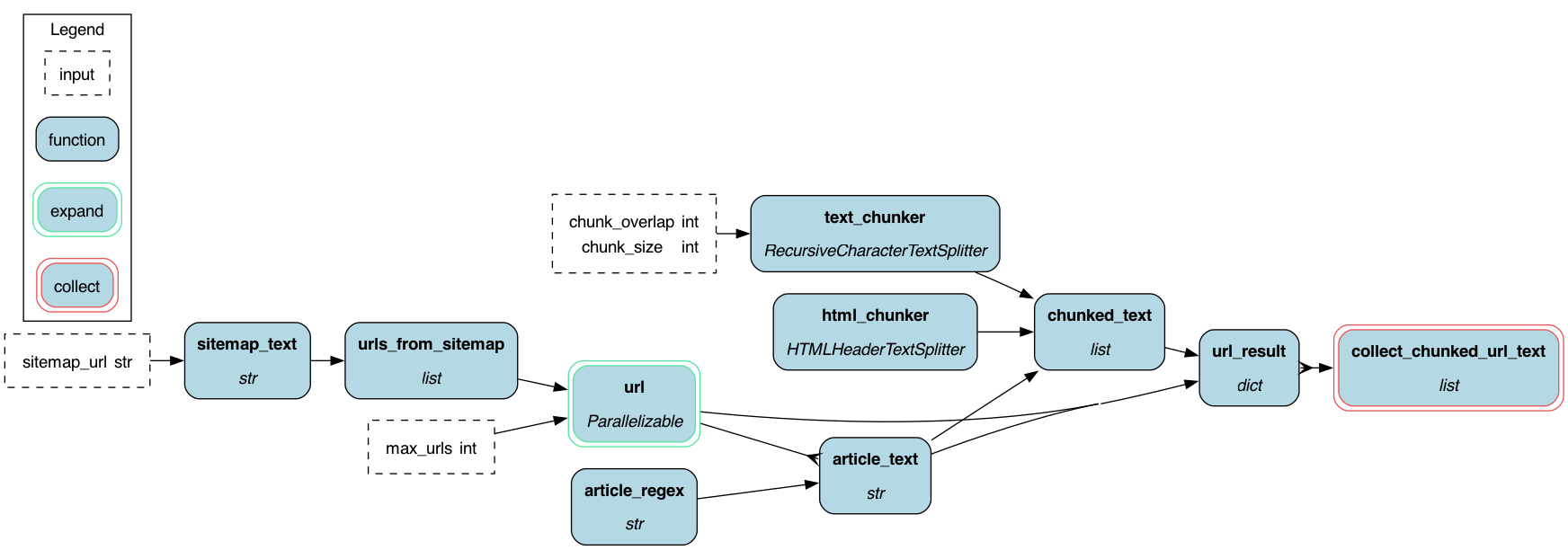
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
from hamilton.execution import executors
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
sphinx_doc_chunking = dataflows.import_module("sphinx_doc_chunking")
# Switch this out for ray, dask, etc. See docs for more info.
remote_executor = executors.MultiThreadingExecutor(max_tasks=20)
dr = (
driver.Builder()
.enable_dynamic_execution(allow_experimental_mode=True)
.with_remote_executor(remote_executor)
.with_config({}) # replace with configuration as appropriate
.with_modules(sphinx_doc_chunking)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[sphinx_doc_chunking.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
from hamilton.execution import executors
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.dagworks import sphinx_doc_chunking
# Switch this out for ray, dask, etc. See docs for more info.
remote_executor = executors.MultiThreadingExecutor(max_tasks=20)
dr = (
driver.Builder()
.enable_dynamic_execution(allow_experimental_mode=True)
.with_remote_executor(remote_executor)
.with_config({}) # replace with configuration as appropriate
.with_modules(sphinx_doc_chunking)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[sphinx_doc_chunking.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(sphinx_doc_chunking, "path/to/save/to")
Purpose of this module
The purpose of this module is to take Sphinx Furo themed documentation, pull the pages, and chunk the text for further processing, e.g. creating embeddings. This is fairly generic code that is easy to change and extend for your purposes. It runs anywhere that python runs, and can be extended to run on Ray, Dask, and even PySpark.
## import sphinx_doc_chunking via the means that you want. See above code.
from hamilton import driver
from hamilton.execution import executors
dr = (
driver.Builder()
.with_modules(sphinx_doc_chunking)
.enable_dynamic_execution(allow_experimental_mode=True)
.with_config({})
## defaults to multi-threading -- and tasks control max concurrency
.with_remote_executor(executors.MultiThreadingExecutor(max_tasks=25))
.build()
)
What you should modify
You'll likely want to:
- play with what does the chunking and settings for that.
- change how URLs are sourced.
- change how text is extracted from a page.
- extend the code to hit an API to get embeddings.
- extend the code to push data to a vector database.
Configuration Options
There is no configuration required for this module.
Limitations
You general multiprocessing caveats apply if you choose an executor other than MultiThreading. For example:
- Serialization -- objects need to be serializable between processes.
- Concurrency/parallelism -- you're in control of this.
- Failures -- you'll need to make your code do the right thing here.
- Memory requirements -- the "collect" (or reduce) step pulls things into memory. If you hit this, this just means you need to redesign your code a little, e.g. write large things to a store and pass pointers.
To extend this to PySpark see the examples folder for the changes required to adjust the code to handle PySpark.
Source code
__init__.py
"""
Things this module does.
1. takes in a sitemap.xml file and creates a list of all the URLs in the file.
2. takes in a list of URLs and pulls the HTML from each URL.
3. it then strips the HTML to the relevant body of HTML. We assume `furo themed sphinx docs`.
html/body/div[class="page"]/div[class="main"]/div[class="content"]/div[class="article-container"]/article
4. it then chunks the HTML into smaller pieces -- returning langchain documents
5. what this doesn't do is create embeddings -- but that would be easy to extend.
"""
import logging
import re
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import requests
from langchain import text_splitter
from langchain_core import documents
from hamilton.htypes import Collect, Parallelizable
def sitemap_text(sitemap_url: str = "https://hamilton.dagworks.io/en/latest/sitemap.xml") -> str:
"""Takes in a sitemap URL and returns the sitemap.xml file.
:param sitemap_url: the URL of sitemap.xml file
:return:
"""
sitemap = requests.get(sitemap_url)
return sitemap.text
def urls_from_sitemap(sitemap_text: str) -> list[str]:
"""Takes in a sitemap.xml file contents and creates a list of all the URLs in the file.
:param sitemap_text: the contents of a sitemap.xml file
:return: list of URLs
"""
urls = re.findall(r"<loc>(.*?)</loc>", sitemap_text)
return urls
def url(urls_from_sitemap: list[str], max_urls: int = 1000) -> Parallelizable[str]:
"""
Takes in a list of URLs for parallel processing.
Note: this could be in a separate module, but it's here for simplicity.
"""
for url in urls_from_sitemap[0:max_urls]:
yield url
# --- Start Parallel Code ---
# The following code is parallelized, once for each url.
# This code could be in a separate module, but it's here for simplicity.
def article_regex() -> str:
"""This assumes you're using the furo theme for sphinx"""
return r'<article role="main" id="furo-main-content">(.*?)</article>'
def article_text(url: str, article_regex: str) -> str:
"""Pulls URL and takes out relevant HTML.
:param url: the url to pull.
:param article_regex: the regext to use to get the contents out of.
:return: sub-portion of the HTML
"""
html = requests.get(url)
article = re.findall(article_regex, html.text, re.DOTALL)
if not article:
raise ValueError(f"No article found in {url}")
text = article[0].strip()
return text
def html_chunker() -> text_splitter.HTMLHeaderTextSplitter:
"""Return HTML chunker object.
:return:
"""
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
]
return text_splitter.HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
def text_chunker(
chunk_size: int = 256, chunk_overlap: int = 32
) -> text_splitter.RecursiveCharacterTextSplitter:
"""Returns the text chunker object.
:param chunk_size:
:param chunk_overlap:
:return:
"""
return text_splitter.RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
def chunked_text(
article_text: str,
html_chunker: text_splitter.HTMLHeaderTextSplitter,
text_chunker: text_splitter.RecursiveCharacterTextSplitter,
) -> list[documents.Document]:
"""This function takes in HTML, chunks it, and then chunks it again.
It then outputs a list of langchain "documents". Multiple documents for one HTML header section is possible.
:param article_text:
:param html_chunker:
:param text_chunker:
:return:
"""
header_splits = html_chunker.split_text(article_text)
splits = text_chunker.split_documents(header_splits)
return splits
def url_result(url: str, article_text: str, chunked_text: list[documents.Document]) -> dict:
"""Function to aggregate what we want to return from parallel processing.
Note: this function is where you could cache the results to a datastore.
:param url:
:param article_text:
:param chunked_text:
:return:
"""
return {"url": url, "article_text": article_text, "chunks": chunked_text}
# --- END Parallel Code ---
def collect_chunked_url_text(url_result: Collect[dict]) -> list:
"""Function to collect the results from parallel processing.
Note: All results for `url_result` are pulled into memory here.
So, if you have a lot of results, you may want to write them to a datastore and pass pointers.
"""
return list(url_result)
if __name__ == "__main__":
# code here for quickly testing the build of the code here.
import __main__ as sphinx_doc_chunking
from hamilton import driver
from hamilton.execution import executors
dr = (
driver.Builder()
.with_modules(sphinx_doc_chunking)
.enable_dynamic_execution(allow_experimental_mode=True)
.with_config({})
.with_local_executor(executors.SynchronousLocalTaskExecutor())
.with_remote_executor(executors.MultiThreadingExecutor(max_tasks=25))
.build()
)
dr.display_all_functions("dag.png")
result = dr.execute(
["collect_chunked_url_text"],
inputs={"chunk_size": 256, "chunk_overlap": 32},
)
# do something with the result...
import pprint
for chunk in result["collect_chunked_url_text"]:
pprint.pprint(chunk)
Requirements
langchain
langchain-core
sf-hamilton[dask]
# optionally install Ray, or Dask, or both
sf-hamilton[ray]
sf-hamilton[visualization]