conversational_rag
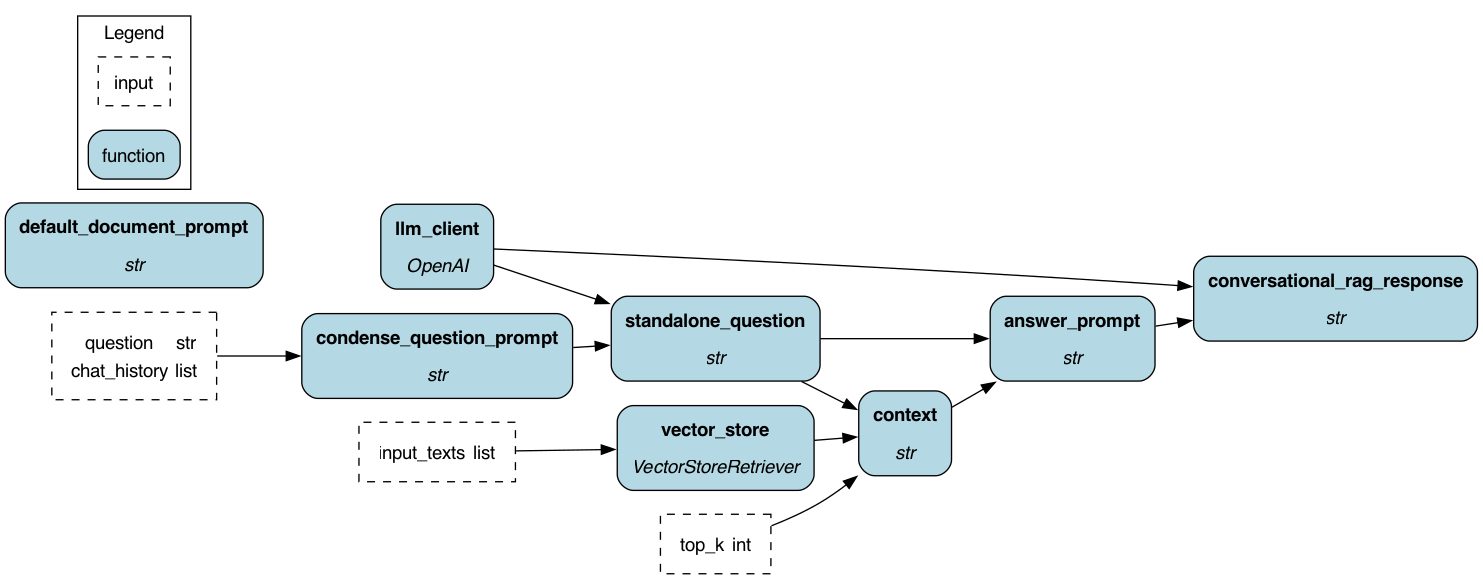
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
conversational_rag = dataflows.import_module("conversational_rag")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(conversational_rag)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[conversational_rag.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.dagworks import conversational_rag
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(conversational_rag)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[conversational_rag.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(conversational_rag, "path/to/save/to")
Purpose of this module
This module shows a conversational retrieval augmented generation (RAG) example using Hamilton. It shows you how you might structure your code with Hamilton to create a RAG pipeline that takes into account conversation.
This example uses FAISS + and in memory vector store and the OpenAI LLM provider. The implementation of the FAISS vector store uses the LangChain wrapper around it. That's because this was the simplest way to get this example up without requiring someone having to host and manage a proper vector store.
The "smarts" in the is pipeline are that it will take a conversation, and then a question, and then rewrite the question based on the conversation to be "standalone". That way the standalone question can be used for the vector store query, as well as a more specific question for the LLM given the found context.
Example Usage
Inputs
These are the defined inputs you can provide.
- input_texts: A list of strings. Each string will be encoded into a vector and stored in the vector store.
- question: A string. This is the question you want to ask the LLM, and vector store which will provide context.
- chat_history: A list of strings. Each string is a line of conversation. They need to be prefixed with "Human" or "AI" to indicate who said it. They should be alternating.
- top_k: An integer. This is the number of vectors to retrieve from the vector store. Defaults to 5.
Overrides
With Hamilton you can easily override a function and provide a value for it. For example if you're iterating you might just want to override these two values before modifying the functions:
- context: if you want to skip going to the vector store and provide the context directly, you can do so by providing this override.
- standalone_question: if you want to skip the rewording of the question, you can provide the standalone question directly.
- answer_prompt: if you want to provide the prompt to pass to the LLM, pass it in as an override.
Execution
You can ask to get back any result of an intermediate function by providing the function name in the execute call.
Here we just ask for the final result, but if you wanted to, you could ask for outputs of any of the functions, which
you can then introspect or log for debugging/evaluation purposes. Note if you want more platform integrations,
you can add adapters that will do this automatically for you, e.g. like we have the PrintLn adapter here.
## import the module
from hamilton import driver
from hamilton import lifecycle
dr = (
driver.Builder()
.with_modules(conversational_rag)
.with_config({})
## this prints the inputs and outputs of each step.
.with_adapters(lifecycle.PrintLn(verbosity=2))
.build()
)
## no chat history -- nothing to rewrite
result = dr.execute(
["conversational_rag_response"],
inputs={
"input_texts": [
"harrison worked at kensho",
"stefan worked at Stitch Fix",
],
"question": "where did stefan work?",
"chat_history": []
},
)
print(result)
## this will now reword the question to then be
## used to query the vector store and the final LLM call.
result = dr.execute(
["conversational_rag_response"],
inputs={
"input_texts": [
"harrison worked at kensho",
"stefan worked at Stitch Fix",
],
"question": "where did he work?",
"chat_history": [
"Human: Who wrote this example?",
"AI: Stefan"
]
},
)
print(result)
How to extend this module
What you'd most likely want to do is:
- Change the vector store (and how embeddings are generated).
- Change the LLM provider.
- Change the context and prompt.
With (1) you can import any vector store/library that you want. You should draw out
the process you would like, and that should then map to Hamilton functions.
With (2) you can import any LLM provider that you want, just use @config.when if you
want to switch between multiple providers.
With (3) you can add more functions that create parts of the prompt.
Configuration Options
There is no configuration needed for this module.
Limitations
You need to have the OPENAI_API_KEY in your environment.
It should be accessible from your code by doing os.environ["OPENAI_API_KEY"].
The code does not check the context length, so it may fail if the context passed is too long for the LLM you send it to.
Source code
__init__.py
import logging
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import openai
# use langchain implementation of vector store
from langchain_community.vectorstores import FAISS
from langchain_core.vectorstores import VectorStoreRetriever
# use langchain embedding wrapper with vector store
from langchain_openai import OpenAIEmbeddings
def standalone_question_prompt(chat_history: list[str], question: str) -> str:
"""Prompt for getting a standalone question given the chat history.
This is then used to query the vector store with.
:param chat_history: the history of the conversation.
:param question: the current user question.
:return: prompt to use.
"""
chat_history_str = "\n".join(chat_history)
return (
"Given the following conversation and a follow up question, "
"rephrase the follow up question to be a standalone question, "
"in its original language.\n\n"
"Chat History:\n"
"{chat_history}\n"
"Follow Up Input: {question}\n"
"Standalone question:"
).format(chat_history=chat_history_str, question=question)
def standalone_question(standalone_question_prompt: str, llm_client: openai.OpenAI) -> str:
"""Asks the LLM to create a standalone question from the prompt.
:param standalone_question_prompt: the prompt with context.
:param llm_client: the llm client to use.
:return: the standalone question.
"""
response = llm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": standalone_question_prompt}],
)
return response.choices[0].message.content
def vector_store(input_texts: list[str]) -> VectorStoreRetriever:
"""A Vector store. This function populates and creates one for querying.
This is a cute function encapsulating the creation of a vector store. In real life
you could replace this with a more complex function, or one that returns a
client to an existing vector store.
:param input_texts: the input "text" i.e. documents to be stored.
:return: a vector store that can be queried against.
"""
vectorstore = FAISS.from_texts(input_texts, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
return retriever
def context(standalone_question: str, vector_store: VectorStoreRetriever, top_k: int = 5) -> str:
"""This function returns the string context to put into a prompt for the RAG model.
It queries the provided vector store for information.
:param standalone_question: the question to use to search the vector store against.
:param vector_store: the vector store to search against.
:param top_k: the number of results to return.
:return: a string with all the context.
"""
_results = vector_store.invoke(standalone_question, search_kwargs={"k": top_k})
return "\n\n".join(map(lambda d: d.page_content, _results))
def answer_prompt(context: str, standalone_question: str) -> str:
"""Creates a prompt that includes the question and context for the LLM to make sense of.
:param context: the information context to use.
:param standalone_question: the user question the LLM should answer.
:return: the full prompt.
"""
template = (
"Answer the question based only on the following context:\n"
"{context}\n\n"
"Question: {question}"
)
return template.format(context=context, question=standalone_question)
def llm_client() -> openai.OpenAI:
"""The LLM client to use for the RAG model."""
return openai.OpenAI()
def conversational_rag_response(answer_prompt: str, llm_client: openai.OpenAI) -> str:
"""Creates the RAG response from the LLM model for the given prompt.
:param answer_prompt: the prompt to send to the LLM.
:param llm_client: the LLM client to use.
:return: the response from the LLM.
"""
response = llm_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": answer_prompt}],
)
return response.choices[0].message.content
if __name__ == "__main__":
import __init__ as conversational_rag
from hamilton import driver, lifecycle
dr = (
driver.Builder()
.with_modules(conversational_rag)
.with_config({})
# this prints the inputs and outputs of each step.
.with_adapters(lifecycle.PrintLn(verbosity=2))
.build()
)
dr.display_all_functions("dag.png")
# shows no question is reworded
print(
dr.execute(
["conversational_rag_response"],
inputs={
"input_texts": [
"harrison worked at kensho",
"stefan worked at Stitch Fix",
],
"question": "where did stefan work?",
"chat_history": [],
},
)
)
# this will now reword the question to then be
# used to query the vector store.
print(
dr.execute(
["conversational_rag_response"],
inputs={
"input_texts": [
"harrison worked at kensho",
"stefan worked at Stitch Fix",
],
"question": "where did he work?",
"chat_history": ["Human: Who wrote this example?", "AI: Stefan"],
},
)
)
Requirements
faiss-cpu
langchain
langchain-community
langchain-openai