xgboost_optuna
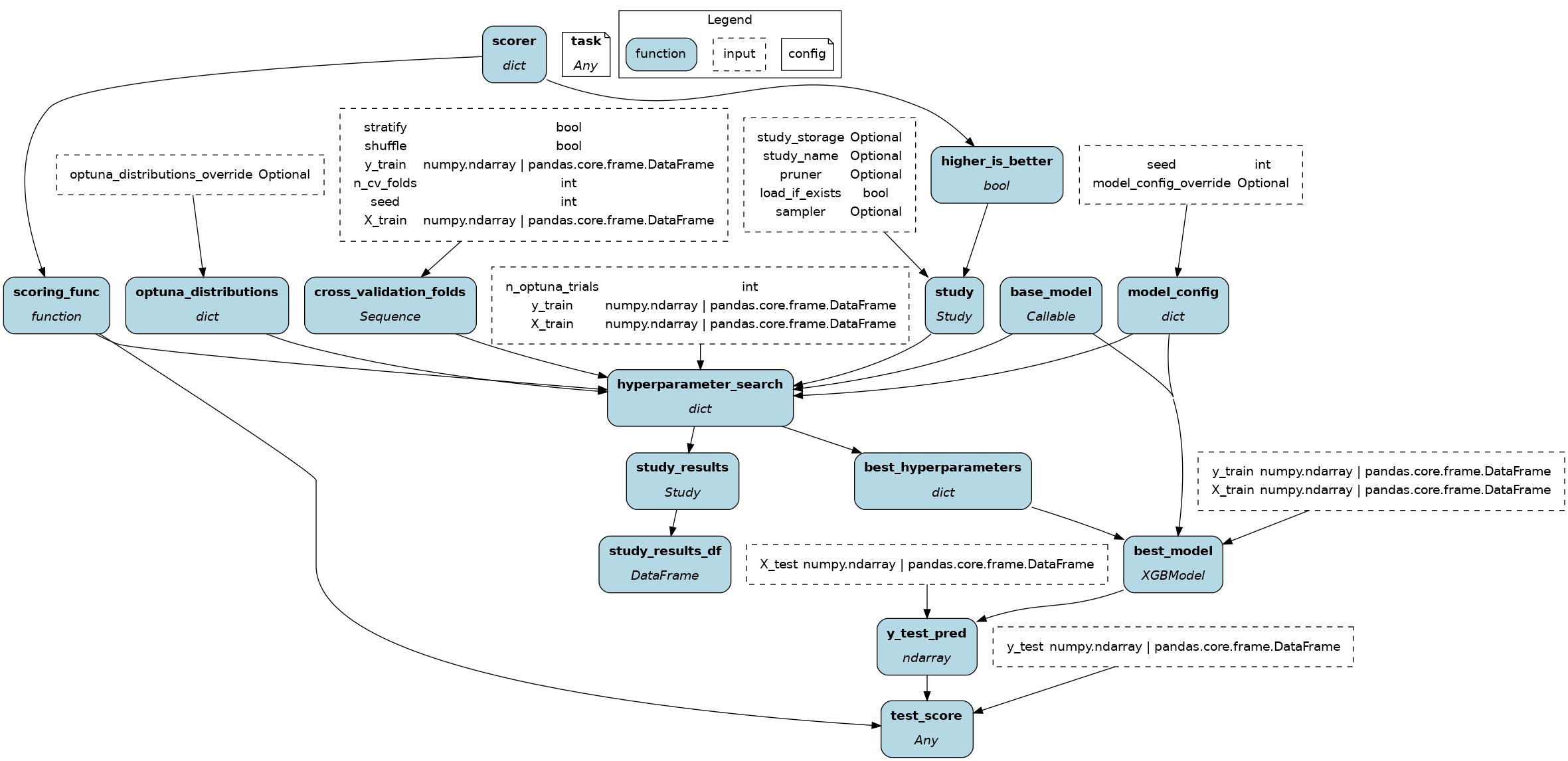
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
xgboost_optuna = dataflows.import_module("xgboost_optuna", "zilto")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(xgboost_optuna)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[xgboost_optuna.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.zilto import xgboost_optuna
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(xgboost_optuna)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[xgboost_optuna.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(xgboost_optuna, "path/to/save/to")
Purpose of this module
This module implements a dataflow to train an XGBoost model with hyperparameter tuning using Optuna.
You give it a 2D arrays for X_train, y_train, X_test, y_test and you are good to go!
Configuration Options
The Hamilton driver can be configured with the following options:
- {"task": "classification"} to use xgboost.XGBClassifier.
- {"task": "regression"} to use xgboost.XGBRegressor.
There are several relevant inputs and override points.
Inputs:
model_config_override: Pass a dictionary to override the XGBoost default config. Warning passing amodel_config_override = {"objective": "binary:logistic}to anXGBRegressoreffectively changes it to anXGBClassifieroptuna_distributions_override: Pass a dictionary of optuna distributions to define the hyperparameter search space.
Overrides:
base_model: can change it to the typexgboost.XGBRankerfor a ranking task orxgboost.dask.DaskXGBClassifierto support Daskscoring_func: can be anysklearn.metricsfunction that acceptsy_trueandy_predas arguments. Remember to set accordinglyhigher_is_betterfor the optimization taskcross_validation_folds: can be any sequence of tuples that define (train_index,validation_index) to train the model with cross-validation overX_train
Limitations
- It is difficult to adapt for distributed Optuna hyperparameter search.
- The current structure makes it difficult to add custom training callbacks to the XGBoost model (can be done to some extent via
model_config_override).
Source code
__init__.py
import logging
from types import FunctionType
from typing import Any, Callable, Optional, Sequence
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import numpy as np
import optuna
import pandas as pd
import xgboost
from optuna.distributions import FloatDistribution, IntDistribution
from sklearn.metrics import accuracy_score, mean_squared_error
from sklearn.model_selection import KFold, StratifiedKFold
from hamilton.function_modifiers import config, extract_fields
def model_config(seed: int = 0, model_config_override: Optional[dict] = None) -> dict:
"""XGBoost model configuration
ref: https://xgboost.readthedocs.io/en/stable/parameter.html
:param model_config_override: Model configuration arguments
"""
config = dict(
device="cpu",
booster="gbtree",
learning_rate=0.05, # alias: eta; typical 0.01 to 0.2
max_depth=3, # typical 3 to 10; will lead to overfitting
gamma=0.1, # alias: min_split_loss; 0 to +inf
n_estimators=200,
colsample_bytree=1, # typical 0.5 to 1
subsample=1, # typical 0.6 to 1
min_child_weight=1, # 0 to +inf; prevent overfitting; too high underfit
max_delta_step=0, # 0 is no constraint; used in imbalanced logistic reg; typical 1 to 10;
reg_alpha=0, # alias alpha; default 0
reg_lambda=1, # alias lambda; default 1
tree_method="hist",
enable_categorical=True,
max_cat_to_onehot=None,
verbosity=2, # 0: silent, 1: warning, 2: info, 3: debug
early_stopping_rounds=20,
)
if model_config_override:
config.update(**model_config_override)
config.update(seed=seed)
return config
def optuna_distributions(optuna_distributions_override: Optional[dict] = None) -> dict:
"""Distributions of hyperparameters to search during optimization
:param optuna_distributions_override: Hyperparameter distributions to explore
"""
config = dict(
n_estimators=IntDistribution(low=250, high=700, step=150),
learning_rate=FloatDistribution(low=0.01, high=0.2, log=True),
max_depth=IntDistribution(low=3, high=10),
gamma=FloatDistribution(low=0.01, high=20, log=True),
colsample_bytree=FloatDistribution(low=0.5, high=1),
min_child_weight=IntDistribution(low=1, high=20, log=True),
max_delta_step=IntDistribution(low=0, high=10),
)
if optuna_distributions_override:
config.update(**optuna_distributions_override)
return config
@config.when(task="classification")
def base_model__classification() -> Callable:
"""Class to instantiate classification model"""
return xgboost.XGBClassifier
@extract_fields(
dict(
scoring_func=FunctionType,
higher_is_better=bool,
)
)
@config.when(task="classification")
def scorer__classification() -> dict:
"""Default scoring function for classification"""
return dict(
scoring_func=accuracy_score,
higher_is_better=True,
)
@config.when(task="regression")
def base_model__regression() -> Callable:
"""Class to instantiate regression model"""
return xgboost.XGBRegressor
@extract_fields(
dict(
scoring_func=FunctionType,
higher_is_better=bool,
)
)
@config.when(task="regression")
def scorer__regression() -> dict:
"""Default scoring function for regression"""
return dict(
scoring_func=mean_squared_error,
higher_is_better=False,
)
def cross_validation_folds(
X_train: np.ndarray | pd.DataFrame,
y_train: np.ndarray | pd.DataFrame,
n_cv_folds: int = 3,
shuffle: bool = True,
stratify: bool = True,
seed: int = 0,
) -> Sequence[tuple]: # [Sequence[int], Sequence[int]]]:
"""Get a list of tuples (train_idx, validation_idx)
Override at the Hamilton execution level to support any cross-validation strategy
"""
if stratify:
kfold = StratifiedKFold(n_splits=n_cv_folds, shuffle=shuffle, random_state=seed)
else:
kfold = KFold(n_splits=n_cv_folds, shuffle=shuffle, random_state=seed)
return list(kfold.split(X_train, y_train))
def study(
higher_is_better: bool,
pruner: Optional[optuna.pruners.BasePruner] = None,
sampler: Optional[optuna.samplers.BaseSampler] = None,
study_storage: Optional[str] = None,
study_name: Optional[str] = None,
load_if_exists: bool = False,
) -> optuna.study.Study:
"""Create an optuna study; use the XGBoost + Optuna integration for pruning
ref: https://github.com/optuna/optuna-examples/blob/main/xgboost/xgboost_integration.py
"""
if pruner is None:
pruner = optuna.pruners.MedianPruner()
return optuna.create_study(
direction="maximize" if higher_is_better else "minimize",
pruner=pruner,
sampler=sampler,
study_name=study_name,
storage=study_storage,
load_if_exists=load_if_exists,
)
@extract_fields(
dict(
study_results=optuna.study.Study,
best_hyperparameters=dict,
)
)
def hyperparameter_search(
X_train: np.ndarray | pd.DataFrame,
y_train: np.ndarray | pd.DataFrame,
cross_validation_folds: Sequence[tuple], # Sequence[tuple[Sequence[int], Sequence[int]]],
base_model: Callable,
model_config: dict,
scoring_func: FunctionType,
optuna_distributions: dict,
study: optuna.study.Study,
n_optuna_trials: int = 10,
) -> dict:
"""Search over the optuna distributions for n trials, trying to achieve
the best validation score.
"""
for _ in range(n_optuna_trials):
trial = study.ask(optuna_distributions)
fold_scores = []
for train_fold, validation_fold in cross_validation_folds:
if isinstance(X_train, pd.DataFrame):
X_train_fold = X_train.iloc[train_fold]
X_validation_fold = X_train.iloc[validation_fold]
else:
X_train_fold = X_train[train_fold]
X_validation_fold = X_train[validation_fold]
if isinstance(y_train, pd.DataFrame):
y_train_fold = y_train.iloc[train_fold]
y_validation_fold = y_train.iloc[validation_fold]
else:
y_train_fold = y_train[train_fold]
y_validation_fold = y_train[validation_fold]
model = base_model(**model_config)
model.set_params(**trial.params)
model.fit(
X_train_fold,
y_train_fold,
eval_set=[(X_validation_fold, y_validation_fold)],
verbose=False,
)
y_validation_fold_pred = model.predict(X_validation_fold)
score = scoring_func(y_true=y_validation_fold, y_pred=y_validation_fold_pred)
fold_scores.append(score)
study.tell(trial, np.mean(fold_scores))
return dict(
study_results=study,
best_hyperparameters=study.best_params,
)
def study_results_df(study_results: optuna.study.Study) -> pd.DataFrame:
"""Return the summary of the optuna study as a dataframe"""
return study_results.trials_dataframe()
def best_model(
X_train: np.ndarray | pd.DataFrame,
y_train: np.ndarray | pd.DataFrame,
base_model: Callable,
model_config: dict,
best_hyperparameters: dict,
) -> xgboost.XGBModel:
"""Train a model with the best hyperparameters"""
model = base_model(**model_config)
model = model.set_params(early_stopping_rounds=None, **best_hyperparameters)
model.fit(X_train, y_train)
return model
def y_test_pred(
best_model: xgboost.XGBModel,
X_test: np.ndarray | pd.DataFrame,
) -> np.ndarray:
"""Get predictions from the best model on the test set"""
return best_model.predict(X_test)
def test_score(
y_test: np.ndarray | pd.DataFrame,
y_test_pred: np.ndarray,
scoring_func: FunctionType,
) -> Any:
"""Score the test predictions from the best model"""
return scoring_func(y_true=y_test, y_pred=y_test_pred)
Requirements
numpy
optuna
pandas
scikit-learn
sf-hamilton[visualization]
xgboost