webscraper
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
from hamilton.execution import executors
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
webscraper = dataflows.import_module("webscraper", "zilto")
# Switch this out for ray, dask, etc. See docs for more info.
remote_executor = executors.MultiThreadingExecutor(max_tasks=20)
dr = (
driver.Builder()
.enable_dynamic_execution(allow_experimental_mode=True)
.with_remote_executor(remote_executor)
.with_config({}) # replace with configuration as appropriate
.with_modules(webscraper)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[webscraper.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
from hamilton.execution import executors
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.zilto import webscraper
# Switch this out for ray, dask, etc. See docs for more info.
remote_executor = executors.MultiThreadingExecutor(max_tasks=20)
dr = (
driver.Builder()
.enable_dynamic_execution(allow_experimental_mode=True)
.with_remote_executor(remote_executor)
.with_config({}) # replace with configuration as appropriate
.with_modules(webscraper)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[webscraper.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(webscraper, "path/to/save/to")
Purpose of this module
This module implements a simple webscraper that collects the specified HTML tags and removes undesirable ones. Simply give it a list of URLs.
Timeout and retry logic for HTTP request is implemented using the tenacity package.
Configuration Options
This module doesn't receive any configuration.
Inputs
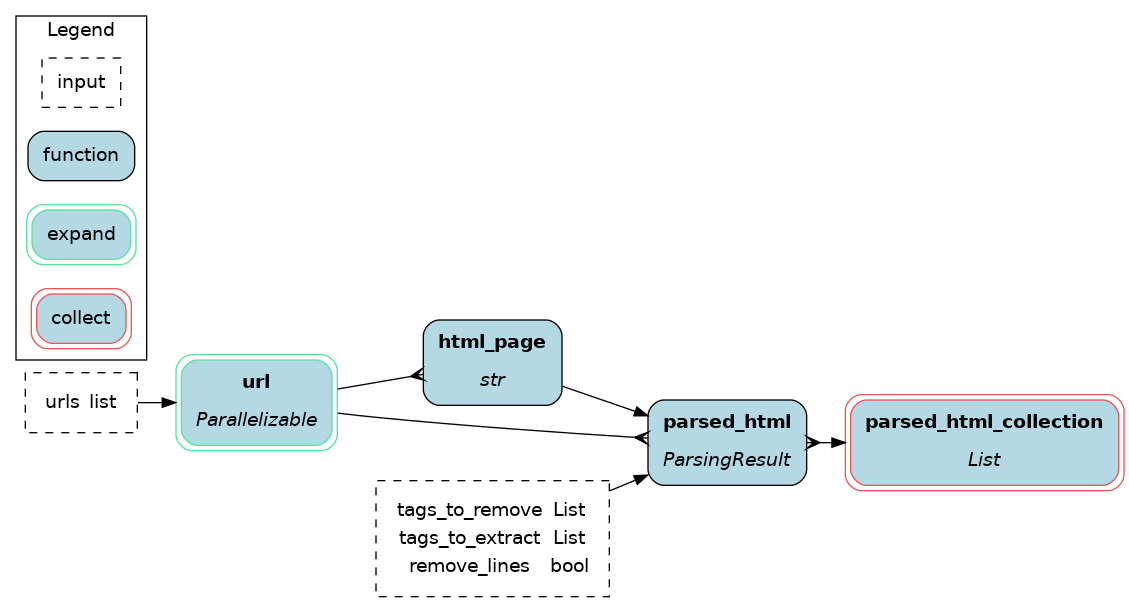
urls(Required): a list of valid url to scrapetags_to_extract: a list of HTML tags to extracttags_to_remove: a list of HTML tags to remove
Overrides
parsed_html: if the function doesn't provide enough flexibility, another parser can be provided as long as it has parametersurlandhtml_pageand outputs aParsingResultobject.
Limitations
- The timeout and retry values need to be edited via the decorator of
html_page().
Source code
__init__.py
import logging
from typing import Any, List
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import lxml # noqa: F401
import requests
from bs4 import BeautifulSoup
from tenacity import retry, stop_after_attempt, wait_random_exponential
import dataclasses
from hamilton.htypes import Collect, Parallelizable
@dataclasses.dataclass
class ParsingResult:
"""Result from the parsing function
:param url: url to the HTML page
:param parsed: the result of the parsing function
"""
url: str
parsed: Any
def url(urls: List[str]) -> Parallelizable[str]:
"""Iterate over the list of urls and create one branch per url
:param urls: list of url to scrape and parse
:return: a single url to scrape and parse
"""
for url_ in urls:
yield url_
@retry(wait=wait_random_exponential(min=1, max=40), stop=stop_after_attempt(3))
def html_page(url: str) -> str:
"""Get the HTML page as string
The tenacity decorator sets the timeout and retry logic
:param url: a single url to request
:return: the HTML page as a string
"""
response = requests.get(url)
response.raise_for_status()
return response.text
def parsed_html(
url: str,
html_page: str,
tags_to_extract: List[str] = ["p", "li", "div"], # noqa: B006
tags_to_remove: List[str] = ["script", "style"], # noqa: B006
) -> ParsingResult:
"""Parse an HTML string using BeautifulSoup
:param url: the url of the requested page
:param html_page: the HTML page associated with the url
:param tags_to_extract: HTML tags to extract and gather
:param tags_to_remove: HTML tags to remove
:return: the ParsingResult which contains the url and the parsing results
"""
soup = BeautifulSoup(html_page, features="lxml")
for tag in tags_to_remove:
for element in soup.find_all(tag):
element.decompose()
content = []
for tag in tags_to_extract:
for element in soup.find_all(tag):
if tag == "a":
href = element.get("href")
if href:
content.append(f"{element.get_text()} ({href})")
else:
content.append(element.get_text(strip=True))
else:
content.append(element.get_text(strip=True))
content = " ".join(content)
return ParsingResult(url=url, parsed=content)
def parsed_html_collection(parsed_html: Collect[ParsingResult]) -> List[ParsingResult]:
"""Collect parallel branches of `parsed_html`
:param parsed_html: receive the ParsingResult associated with each url
:return: list of ParsingResult
"""
return list(parsed_html)
Requirements
beautifulsoup4
lxml
requests
sf-hamilton[visualization]