text_summarization
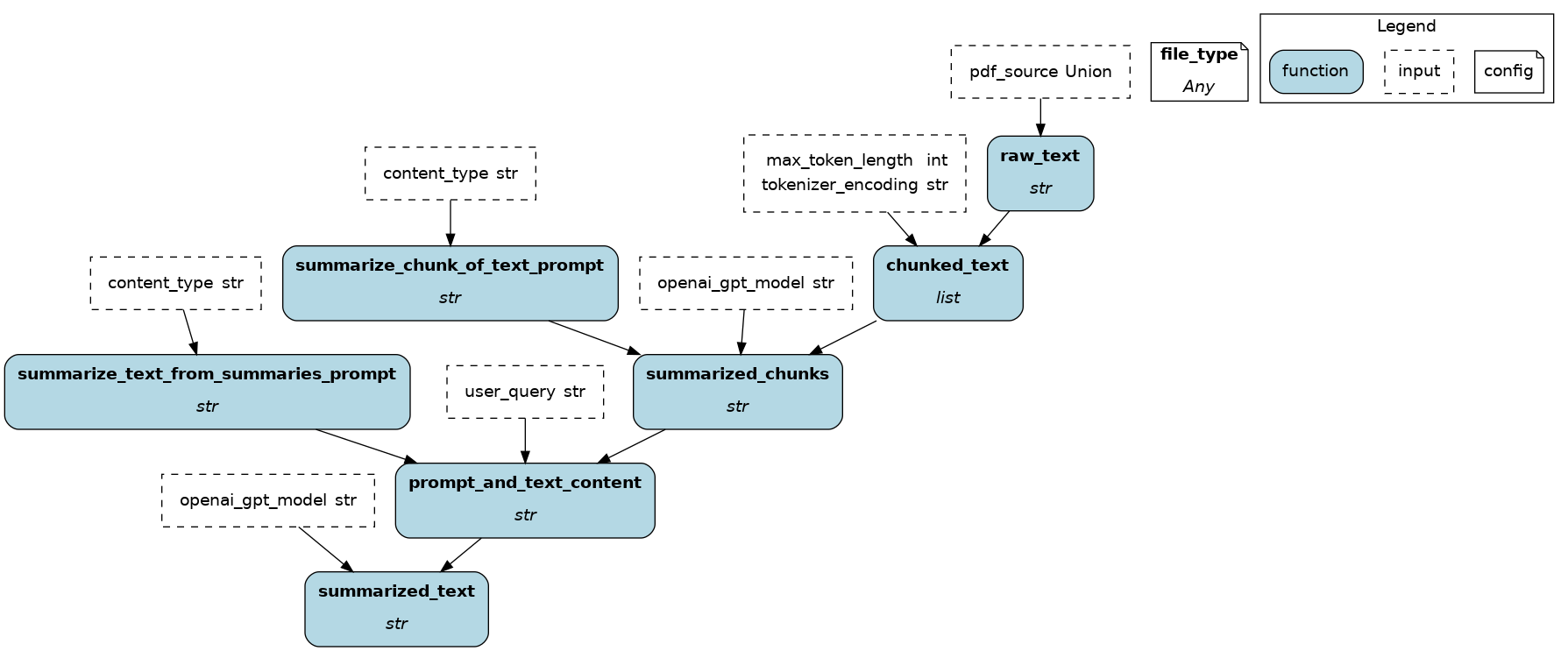
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
text_summarization = dataflows.import_module("text_summarization", "zilto")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(text_summarization)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[text_summarization.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.zilto import text_summarization
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(text_summarization)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[text_summarization.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(text_summarization, "path/to/save/to")
Purpose of this module
This module implements a dataflow to summarize text hitting the OpenAI API.
You can pass in PDFs, or just text and it will get chunked and summarized by the OpenAI API.
Configuration Options
This module can be configured with the following options:
- {"file_type": "pdf"} to read PDFs.
- {"file_type": "text"} to read a text file.
- {} to have
raw_textbe passed in.
Limitations
This module is limited to OpenAI.
It does not check the context length, so it may fail if the context is too long.
Source code
__init__.py
import concurrent
import logging
import tempfile
from typing import Generator, Union
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import openai
import tiktoken
from pypdf import PdfReader
from tenacity import retry, stop_after_attempt, wait_random_exponential
from tqdm import tqdm
from hamilton.function_modifiers import config
def summarize_chunk_of_text_prompt(content_type: str = "an academic paper") -> str:
"""Base prompt for summarizing chunks of text."""
return f"Summarize this text from {content_type}. Extract any key points with reasoning.\n\nContent:"
def summarize_text_from_summaries_prompt(content_type: str = "an academic paper") -> str:
"""Prompt for summarizing a paper from a list of summaries."""
return f"""Write a summary collated from this collection of key points extracted from {content_type}.
The summary should highlight the core argument, conclusions and evidence, and answer the user's query.
User query: {{query}}
The summary should be structured in bulleted lists following the headings Core Argument, Evidence, and Conclusions.
Key points:\n{{results}}\nSummary:\n"""
@config.when(file_type="pdf")
def raw_text__pdf(pdf_source: Union[str, bytes, tempfile.SpooledTemporaryFile]) -> str:
"""Takes a filepath to a PDF and returns a string of the PDF's contents
:param pdf_source: the path, or the temporary file, to the PDF.
:return: the text of the PDF.
"""
reader = PdfReader(pdf_source)
_pdf_text = ""
page_number = 0
for page in reader.pages:
page_number += 1
_pdf_text += page.extract_text() + f"\nPage Number: {page_number}"
return _pdf_text
@config.when(file_type="txt")
def raw_text__txt(text_file: Union[str, tempfile.SpooledTemporaryFile]) -> str:
"""Takes a filepath to a text file and returns a string of the text file's contents
:param text_file: the path, or the temporary file, to the text file.
:return: the contents of the file as a string.
"""
with open(text_file) as f:
return f.read()
def _create_chunks(text: str, n: int, tokenizer: tiktoken.Encoding) -> Generator[str, None, None]:
"""Helper function. Returns successive n-sized chunks from provided text.
Split a text into smaller chunks of size n, preferably ending at the end of a sentence
:param text:
:param n:
:param tokenizer:
:return:
"""
tokens = tokenizer.encode(text)
i = 0
while i < len(tokens):
# Find the nearest end of sentence within a range of 0.5 * n and 1.5 * n tokens
j = min(i + int(1.5 * n), len(tokens))
while j > i + int(0.5 * n):
# Decode the tokens and check for full stop or newline
chunk = tokenizer.decode(tokens[i:j])
if chunk.endswith(".") or chunk.endswith("\n"):
break
j -= 1
# If no end of sentence found, use n tokens as the chunk size
if j == i + int(0.5 * n):
j = min(i + n, len(tokens))
yield tokens[i:j]
i = j
def chunked_text(
raw_text: str, tokenizer_encoding: str = "cl100k_base", max_token_length: int = 1500
) -> list[str]:
"""Chunks the pdf text into smaller chunks of size max_token_length.
:param raw_text: the Series of individual pdf texts to chunk.
:param max_token_length: the maximum length of tokens in each chunk.
:param tokenizer_encoding: the encoding to use for the tokenizer.
:return: Series of chunked pdf text. Each element is a list of chunks.
"""
tokenizer = tiktoken.get_encoding(tokenizer_encoding)
_encoded_chunks = _create_chunks(raw_text, max_token_length, tokenizer)
_decoded_chunks = [tokenizer.decode(chunk) for chunk in _encoded_chunks]
return _decoded_chunks
@retry(wait=wait_random_exponential(min=1, max=40), stop=stop_after_attempt(3))
def _summarize_chunk(content: str, template_prompt: str, openai_gpt_model: str) -> str:
"""This function applies a prompt to some input content. In this case it returns a summarized chunk of text.
:param content: the content to summarize.
:param template_prompt: the prompt template to use to put the content into.
:param openai_gpt_model: the openai gpt model to use.
:return: the response from the openai API.
"""
prompt = template_prompt + content
response = openai.ChatCompletion.create(
model=openai_gpt_model, messages=[{"role": "user", "content": prompt}], temperature=0
)
return response["choices"][0]["message"]["content"]
def summarized_chunks(
chunked_text: list[str], summarize_chunk_of_text_prompt: str, openai_gpt_model: str
) -> str:
"""Summarizes a series of chunks of text.
Note: this takes the first result from the top_n_related_articles series and summarizes it. This is because
the top_n_related_articles series is sorted by relatedness, so the first result is the most related.
:param chunked_text: a list of chunks of text for an article.
:param summarize_chunk_of_text_prompt: the prompt to use to summarize each chunk of text.
:param openai_gpt_model: the openai gpt model to use.
:return: a single string of each chunk of text summarized, concatenated together.
"""
_summarized_text = ""
with concurrent.futures.ThreadPoolExecutor(max_workers=len(chunked_text)) as executor:
futures = [
executor.submit(
_summarize_chunk, chunk, summarize_chunk_of_text_prompt, openai_gpt_model
)
for chunk in chunked_text
]
with tqdm(total=len(chunked_text)) as pbar:
for _ in concurrent.futures.as_completed(futures):
pbar.update(1)
for future in futures:
data = future.result()
_summarized_text += data
return _summarized_text
def prompt_and_text_content(
summarized_chunks: str,
summarize_text_from_summaries_prompt: str,
user_query: str,
) -> str:
"""Creates the prompt for summarizing the text from the summarized chunks of the pdf.
:param summarized_chunks: a long string of chunked summaries of a file.
:param summarize_text_from_summaries_prompt: the template to use to summarize the chunks.
:param user_query: the original user query.
:return: the prompt to use to summarize the chunks.
"""
return summarize_text_from_summaries_prompt.format(query=user_query, results=summarized_chunks)
def summarized_text(
prompt_and_text_content: str,
openai_gpt_model: str,
) -> str:
"""Summarizes the text from the summarized chunks of the pdf.
:param prompt_and_text_content: the prompt and content to send over.
:param openai_gpt_model: which openai gpt model to use.
:return: the string response from the openai API.
"""
response = openai.ChatCompletion.create(
model=openai_gpt_model,
messages=[
{
"role": "user",
"content": prompt_and_text_content,
}
],
temperature=0,
)
return response["choices"][0]["message"]["content"]
if __name__ == "__main__":
# run as a script to test Hamilton's execution
import __init__ as text_summarization
from hamilton import base, driver
dr = driver.Driver(
{"file_type": "pdf"},
text_summarization,
adapter=base.DefaultAdapter(),
)
# create the DAG image
dr.display_all_functions("dag", {"format": "png", "view": False}, orient="TB")
Requirements
openai
PyPDF2
tenacity
tiktoken
tqdm