lancedb_vdb
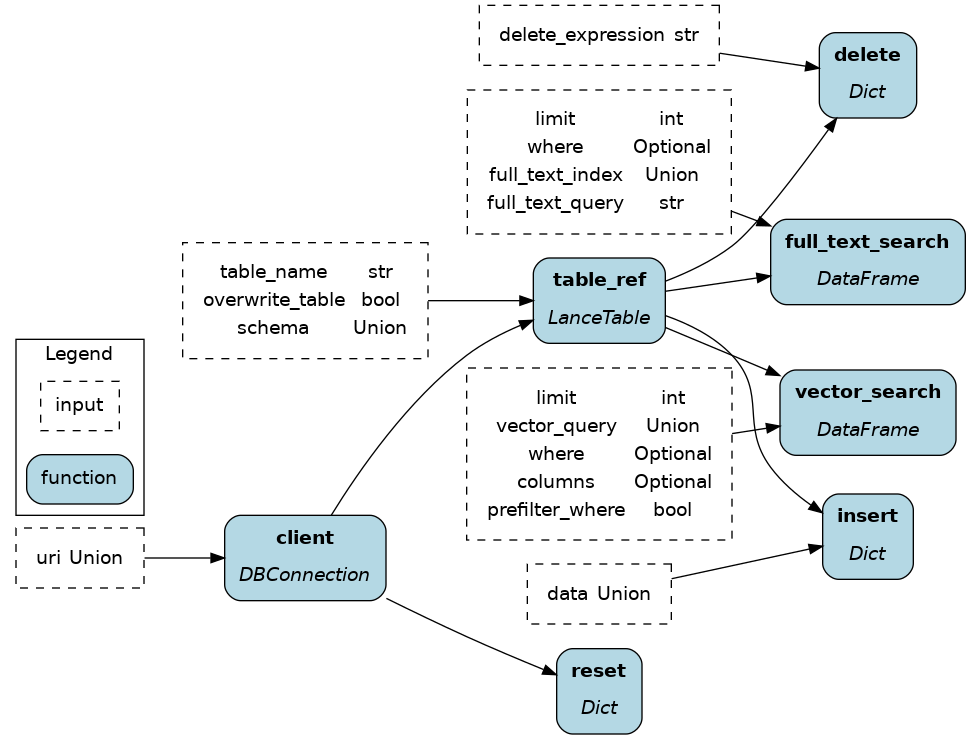
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
lancedb_vdb = dataflows.import_module("lancedb_vdb", "zilto")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(lancedb_vdb)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[lancedb_vdb.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.zilto import lancedb_vdb
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(lancedb_vdb)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[lancedb_vdb.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(lancedb_vdb, "path/to/save/to")
Purpose of this module
This module implements vector and full-text search using LanceDB.
Configuration Options
This module doesn't receive any configuration.
Inputs:
url: The url to the local LanceDB instance.table_name: The name of the table to interact with.schema: To create a new table, you need to specify a pyarrow schema.vector_query: The embedding vector of the text query.full_text_query: The text content to search for in the columnsfull_text_index.
Limitations
- Full-text search needs to rebuild the index to include newly added data. By default
rebuild_index=Truewill rebuild the index on each call tofull_text_search()for safety. Passrebuild_index=Falsewhen making multiple search queries without adding new data. insert()anddelete()returns the number of rows added and deleted, which requires reading the table in a Pyarrow table. This could impact performance if the table gets very large or push / delete are highly frequent.
Source code
__init__.py
import logging
from pathlib import Path
from typing import Dict, Iterable, List, Optional, Union
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import lancedb
import numpy as np
import pandas as pd
import pyarrow as pa
from lancedb.pydantic import LanceModel
from hamilton.function_modifiers import tag
VectorType = Union[list, np.ndarray, pa.Array, pa.ChunkedArray]
DataType = Union[Dict, List[Dict], pd.DataFrame, pa.Table, Iterable[pa.RecordBatch]]
TableSchema = Union[pa.Schema, LanceModel]
def client(uri: Union[str, Path] = "./.lancedb") -> lancedb.DBConnection:
"""Create a LanceDB connection.
:param uri: path to local LanceDB
:return: connection to LanceDB instance.
"""
return lancedb.connect(uri=uri)
def _create_table(
client: lancedb.DBConnection,
table_name: str,
schema: Optional[TableSchema] = None,
overwrite_table: bool = False,
) -> lancedb.db.LanceTable:
"""Create a new table based on schema."""
mode = "overwrite" if overwrite_table else "create"
table = client.create_table(name=table_name, schema=schema, mode=mode)
return table
@tag(side_effect="True")
def table_ref(
client: lancedb.DBConnection,
table_name: str,
schema: Optional[TableSchema] = None,
overwrite_table: bool = False,
) -> lancedb.db.LanceTable:
"""Create or reference a LanceDB table
:param vdb_client: LanceDB connection.
:param table_name: Name of the table.
:param schema: Pyarrow schema defining the table schema.
:param overwrite_table: If True, overwrite existing table
:return: Reference to existing or newly created table.
"""
try:
table = client.open_table(table_name)
except FileNotFoundError as e:
if schema is None:
raise ValueError("`schema` must be provided to create table.") from e
table = _create_table(
client=client,
table_name=table_name,
schema=schema,
overwrite_table=overwrite_table,
)
return table
@tag(side_effect="True")
def reset(client: lancedb.DBConnection) -> Dict[str, List[str]]:
"""Drop all existing tables.
:param vdb_client: LanceDB connection.
:return: dictionary containing all the dropped tables.
"""
tables_dropped = []
for table_name in client.table_names():
client.drop_table(table_name)
tables_dropped.append(table_name)
return dict(tables_dropped=tables_dropped)
@tag(side_effect="True")
def insert(table_ref: lancedb.db.LanceTable, data: DataType) -> Dict:
"""Push new data to the specified table.
:param table_ref: Reference to the LanceDB table.
:param data: Data to add to the table. Ref: https://lancedb.github.io/lancedb/guides/tables/#adding-to-a-table
:return: Reference to the table and number of rows added
"""
n_rows_before = table_ref.to_arrow().shape[0]
table_ref.add(data)
n_rows_after = table_ref.to_arrow().shape[0]
n_rows_added = n_rows_after - n_rows_before
return dict(table=table_ref, n_rows_added=n_rows_added)
@tag(side_effect="True")
def delete(table_ref: lancedb.db.LanceTable, delete_expression: str) -> Dict:
"""Delete existing data using an SQL expression.
:param table_ref: Reference to the LanceDB table.
:param data: Expression to select data. Ref: https://lancedb.github.io/lancedb/sql/
:return: Reference to the table and number of rows deleted
"""
n_rows_before = table_ref.to_arrow().shape[0]
table_ref.delete(delete_expression)
n_rows_after = table_ref.to_arrow().shape[0]
n_rows_deleted = n_rows_before - n_rows_after
return dict(table=table_ref, n_rows_deleted=n_rows_deleted)
def vector_search(
table_ref: lancedb.db.LanceTable,
vector_query: VectorType,
columns: Optional[List[str]] = None,
where: Optional[str] = None,
prefilter_where: bool = False,
limit: int = 10,
) -> pd.DataFrame:
"""Search database using an embedding vector.
:param table_ref: table to search
:param vector_query: embedding of the query
:param columns: columns to include in the results
:param where: SQL where clause to pre- or post-filter results
:param prefilter_where: If True filter rows before search else filter after search
:param limit: number of rows to return
:return: A dataframe of results
"""
query_ = (
table_ref.search(
query=vector_query,
query_type="vector",
vector_column_name="vector",
)
.select(columns=columns)
.where(where, prefilter=prefilter_where)
.limit(limit=limit)
)
return query_.to_pandas()
def full_text_search(
table_ref: lancedb.db.LanceTable,
full_text_query: str,
full_text_index: Union[str, List[str]],
where: Optional[str] = None,
limit: int = 10,
rebuild_index: bool = True,
) -> pd.DataFrame:
"""Search database using an embedding vector.
:param table_ref: table to search
:param full_text_query: text query
:param full_text_index: one or more text columns to search
:param where: SQL where clause to pre- or post-filter results
:param limit: number of rows to return
:param rebuild_index: If True rebuild the index
:return: A dataframe of results
"""
# NOTE. Currently, the index needs to be recreated whenever data is added
# ref: https://lancedb.github.io/lancedb/fts/#installation
if rebuild_index:
table_ref.create_fts_index(full_text_index)
query_ = (
table_ref.search(query=full_text_query, query_type="fts")
.select(full_text_index)
.where(where)
.limit(limit)
)
return query_.to_pandas()
Requirements
lancedb
numpy
pyarrow
sf-hamilton[visualization]