hello_world
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
hello_world = dataflows.import_module("hello_world", "skrawcz")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(hello_world)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[hello_world.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.skrawcz import hello_world
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(hello_world)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[hello_world.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(hello_world, "path/to/save/to")
Purpose of this module
This module implements a hello world dataflow to show transforming columns from a dataframe.
You can pass in your own values for spend & signups, or use the default.
Configuration Options
This module can be configured with the following options:
- {"default": "True"} to run it without any inputs.
- {} to have to pass in
spendandsignups.
Limitations
None to really note.
Source code
__init__.py
import logging
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import pandas as pd
from hamilton.function_modifiers import config, extract_columns
@extract_columns("spend", "signups")
@config.when(default="True")
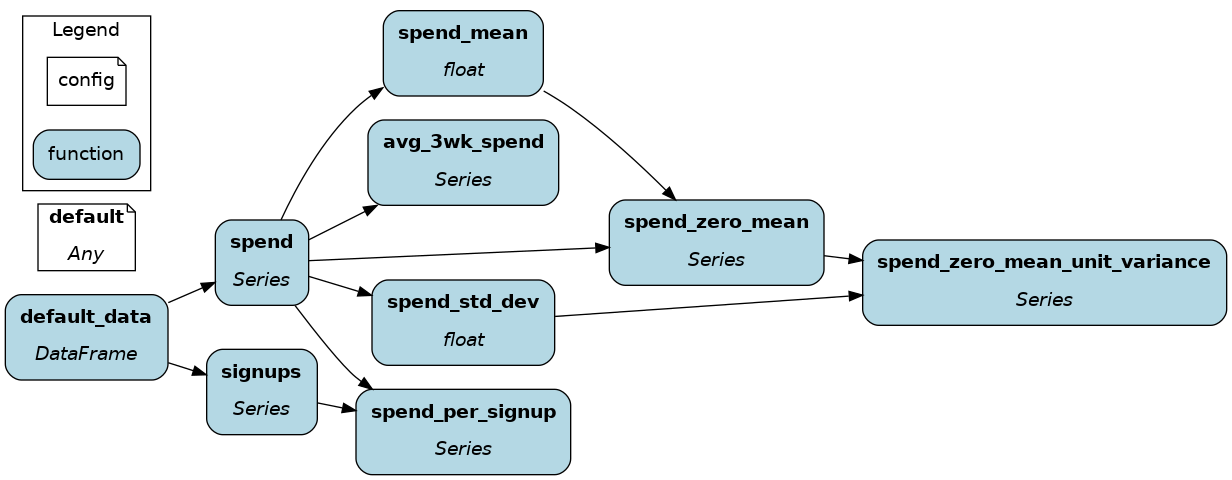
def default_data() -> pd.DataFrame:
return pd.DataFrame(
{
"signups": pd.Series([1, 10, 50, 100, 200, 400]),
"spend": pd.Series([10, 10, 20, 40, 40, 50]),
}
)
def avg_3wk_spend(spend: pd.Series) -> pd.Series:
"""Rolling 3 week average spend."""
return spend.rolling(3).mean()
def spend_per_signup(spend: pd.Series, signups: pd.Series) -> pd.Series:
"""The cost per signup in relation to spend."""
return spend / signups
def spend_mean(spend: pd.Series) -> float:
"""Shows function creating a scalar. In this case it computes the mean of the entire column."""
return spend.mean()
def spend_zero_mean(spend: pd.Series, spend_mean: float) -> pd.Series:
"""Shows function that takes a scalar. In this case to zero mean spend."""
return spend - spend_mean
def spend_std_dev(spend: pd.Series) -> float:
"""Function that computes the standard deviation of the spend column."""
return spend.std()
def spend_zero_mean_unit_variance(spend_zero_mean: pd.Series, spend_std_dev: float) -> pd.Series:
"""Function showing one way to make spend have zero mean and unit variance."""
return spend_zero_mean / spend_std_dev
if __name__ == "__main__":
# run as a script to test Hamilton's execution
import __init__ as hello_world
from hamilton import base, driver
dr = driver.Driver(
{"default": "True"},
hello_world,
adapter=base.DefaultAdapter(),
)
# create the DAG image
dr.display_all_functions("dag", {"format": "png", "view": False})
Requirements
pandas