fine_tuning
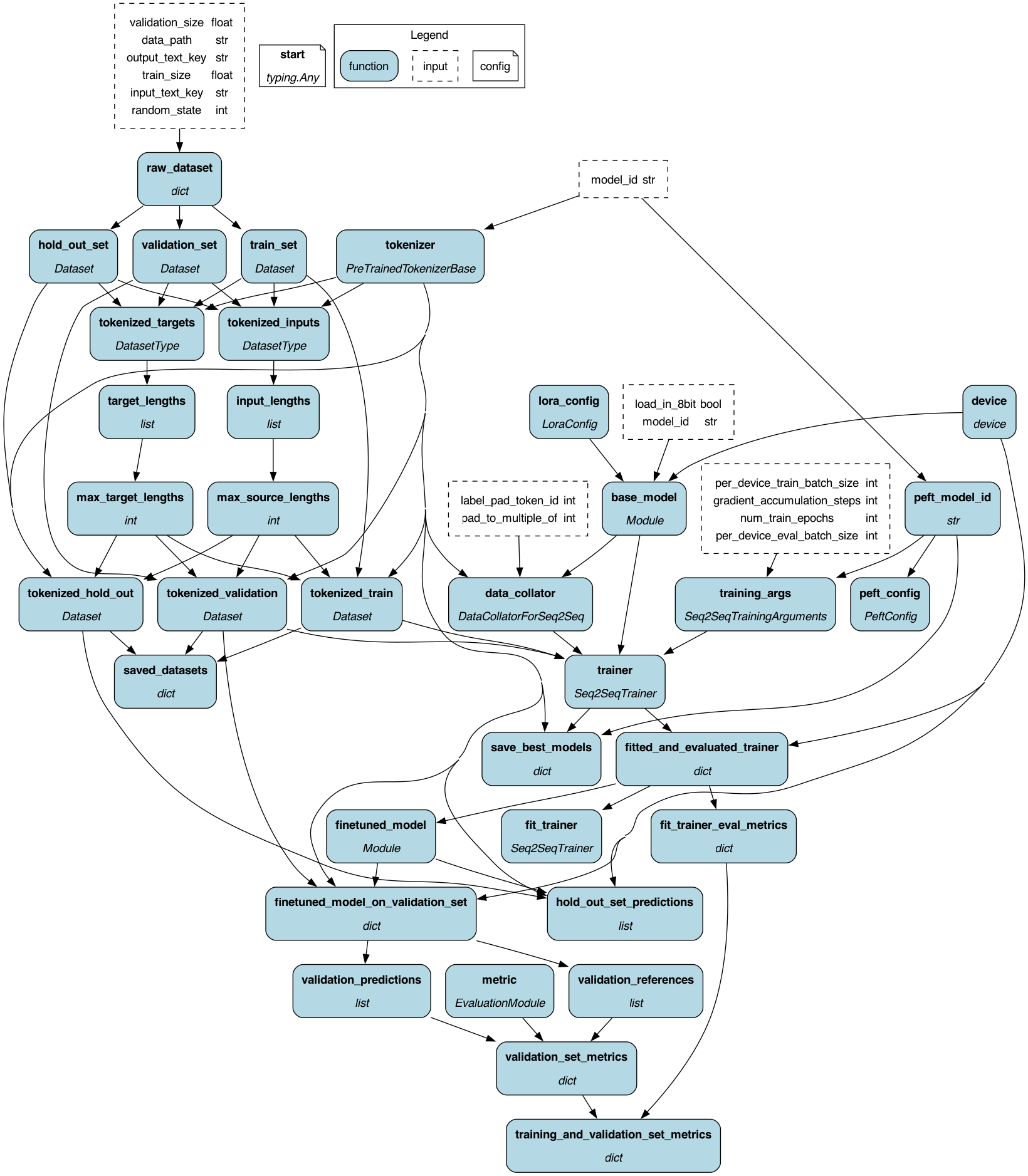
To get started:
Dynamically pull and run
from hamilton import dataflows, driver
# downloads into ~/.hamilton/dataflows and loads the module -- WARNING: ensure you know what code you're importing!
fine_tuning = dataflows.import_module("fine_tuning", "skrawcz")
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(fine_tuning)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[fine_tuning.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Use published library version
pip install sf-hamilton-contrib --upgrade # make sure you have the latest
from hamilton import dataflows, driver
# Make sure you've done - `pip install sf-hamilton-contrib --upgrade`
from hamilton.contrib.user.skrawcz import fine_tuning
dr = (
driver.Builder()
.with_config({}) # replace with configuration as appropriate
.with_modules(fine_tuning)
.build()
)
# If you have sf-hamilton[visualization] installed, you can see the dataflow graph
# In a notebook this will show an image, else pass in arguments to save to a file
# dr.display_all_functions()
# Execute the dataflow, specifying what you want back. Will return a dictionary.
result = dr.execute(
[fine_tuning.CHANGE_ME, ...], # this specifies what you want back
inputs={...} # pass in inputs as appropriate
)
Modify for your needs
Now if you want to modify the dataflow, you can copy it to a new folder (renaming is possible), and modify it there.
dataflows.copy(fine_tuning, "path/to/save/to")
Purpose of this module
This module shows you how to fine-tune an LLM model. This code is inspired by this fine-tuning code.
Specifically the code here, shows Supervised Fine-Tuning (SFT) for dialogue. This approach instructs the model to be more useful to directly respond to a question, rather than optimizing over an entire dialogue. SFT is the most common type of fine-tuning, as the other two options, Pre-training for Completion, and RLHF, required more to work. Pre-training requires more computational power, while RLHF requires higher-quality dialogue data.
This code should work on a regular CPU (in a docker container), which will allow you to test out the code locally without any additional setup. This specific approach this code uses is LoRA (low-rank adaptation of large language models), which means that only a subset of the LLM's parameters are tweaked and prevents over-fitting.
Note: if you have issues running this on MacOS, reach out, we might be able to help.
What is fine-tuning?
Fine-tuning is when a pre-trained model, in this context a foundational model, is customized using additional data to adjust its responses for a specific task. This is a good way to adjust an off-the-shelf, i.e. pretrained model, to provide more responses that are more contextually relevant to your use case.
FLAN LLM
This example is based on using Google's Fine-tuned LAnguage Net (FLAN) models hosted on HuggingFace. The larger the model, the longer it will take to fine-tune, and the more memory you'll need for it. The code here was validated to run on docker using the smallest FLAN model ("model_id": "google/flan-t5-small") on a Mac that's a few years old.
What type of functionality is in this module?
The module uses libraries such as numpy, pandas, plotly, torch, sklearn, peft, evaluate, datasets, and transformers.
It shows a basic process of:
a. Loading data and tokenizing it and setting up some tokenization parameters.
b. Splitting data into training, validation, and hold out sets.
c. Fine-tuning the model using LoRA.
d. Evaluating the fine-tuned model using the rouge metric.
You should be able to read the module top to bottom which corresponds roughly to the order of execution.
How might I use this module?
To use this module you'll need to do the following:
- Data. The data set should be list of JSON objects, where each entry in the list is an object that has the "question" and
and also the "answer" to that question. You will provide the name of the keys for these fields as input to run the code.
e.g. you should be able to do
json.load(f)and it would return a list of dictionaries, e.g. something like this:
[
{
"question": "What is the meaning of life?",
"reply": "42"
},
{
"question": "What is Hamilton?",
"reply": "..."
},
...
]
You would then pass in as inputs to execution "data_path":PATH_TO_THIS_FILE as well as "input_text_key":"question" and "output_text_key":"reply".
- Instantiate the driver. Use
{"start": "base"}as configuration to run with to use a raw base LLM to finetune. - Pick your LLM.
"model_id":"google/mt5-small"is what we recommend to start, but you can change it to any of the models that the transformers library supports forAutoModelForSeq2SeqLMmodels. - Run the code.
## instantiate the driver with this module however you want
result = dr.execute(
[ ## some suggested outputs -- see the visualization/code to understand what these are
"save_best_models",
"hold_out_set_predictions",
"training_and_validation_set_metrics",
"finetuned_model_on_validation_set",
],
inputs={
"model_id": "google/flan-t5-small", ## the base model you want to fine-tune
"data_path": "example-support-dataset.json", ## the path to your dataset
"input_text_key": "question", ## the key in the json object that has the input text
"output_text_key": "gpt4_replies_target", ## the key in the json object that has the target output text
},
)
Running the code in a docker container
The easiest way to run this code is to use a docker container, unless you have experience with
GPUs. After writing a module that uses the code here, e.g. YOUR_RUN_FILE.py, you can create a dockerfile
that looks like this to then execute your fine-tuning code. Note, replace example-support-dataset.json with
your dataset that you want to fine-tune on.
FROM python:3.10-slim-bullseye
WORKDIR /app
## install graphviz backend
RUN apt-get update \
&& apt-get autoremove -yqq --purge \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
## change this to your data set if you want to load
## it into the container
COPY example-support-dataset.json .
COPY . .
EXPOSE 8080:8080
## run the code that you wrote that invokes this module
CMD python YOUR_RUN_FILE.py
Then to run this it's just:
docker build -t YOUR_IMAGE_NAME .
docker run YOUR_IMAGE_NAME
Configuration Options
{"start": "base"}Suggested configuration to run with to use a raw base LLM to finetune.{"start": "presaved"}Use this if you want to load an already fine-tuned model and then just eval it.
Limitations
The code here will likely not solve all your LLM troubles, but it can show you how to fine-tune an LLM using parameter-efficient techniques such as LoRA.
This code is currently set up to work with dataset and transformer libraries. It could be modified to work with other libraries.
The code here is all in a single module, it could be split out to be more modular, e.g. data loading vs tokenization vs finetuning vs evaluation.
Source code
__init__.py
import json
import logging
from functools import partial
from typing import Dict
logger = logging.getLogger(__name__)
from hamilton import contrib
with contrib.catch_import_errors(__name__, __file__, logger):
import evaluate
import numpy as np
import pandas as pd
import torch
from datasets import Dataset, concatenate_datasets
from datasets.combine import DatasetType
from peft import (
LoraConfig,
PeftConfig,
PeftModel,
TaskType,
get_peft_model,
prepare_model_for_int8_training,
)
from sklearn.model_selection import train_test_split
from tqdm import tqdm
from transformers import (
AutoModelForSeq2SeqLM,
AutoTokenizer,
DataCollatorForSeq2Seq,
PreTrainedTokenizerBase,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
)
from hamilton.function_modifiers import extract_fields
from hamilton.function_modifiers.configuration import config
@extract_fields({"train_set": Dataset, "validation_set": Dataset, "hold_out_set": Dataset})
def raw_dataset(
data_path: str,
random_state: int = 42,
train_size: float = 0.95,
validation_size: float = 0.8,
input_text_key: str = "question",
output_text_key: str = "reply",
) -> Dict[str, Dataset]:
"""Loads the raw dataset from disk and splits it into train and test sets.
:param data_path: the path to the dataset.
:param random_state: the random state for the train/test split.
:param train_size: the train size as a fraction of the dataset.
:param input_text_key: the key to use to get the input text from what was loaded.
:param output_text_key: the key to use to get the output text from what was loaded.
:return: dictionary with the train, validation, and inference sets.
"""
with open(data_path, "r") as f:
data = json.load(f)
format_data = []
for sample in data:
format_data.append(
{
"input_text": sample[input_text_key],
"output_text": sample[output_text_key],
}
)
format_data = pd.DataFrame(format_data)
train, test = train_test_split(format_data, random_state=random_state, train_size=train_size)
# split the test set into a validation set and inference set
validation, inference = train_test_split(
test, random_state=random_state, train_size=validation_size
)
dataset_train = Dataset.from_pandas(train)
dataset_validation = Dataset.from_pandas(validation)
dataset_inference = Dataset.from_pandas(inference)
return {
"train_set": dataset_train,
"validation_set": dataset_validation,
"hold_out_set": dataset_inference,
}
def tokenizer(
model_id: str,
) -> PreTrainedTokenizerBase:
"""The tokenizer we're going to use to tokenize text.
:param model_id: the model id that corresponds to what huggingface knows about.
:return: the tokenizer to use.
"""
tokenizer = AutoTokenizer.from_pretrained(model_id)
return tokenizer
def tokenized_inputs(
train_set: Dataset,
validation_set: Dataset,
hold_out_set: Dataset,
tokenizer: PreTrainedTokenizerBase,
) -> DatasetType:
"""Tokenizes the inputs from all the datasets and creates a single data set with them.
This is different from the tokenized_train, tokenized_validation, and tokenized_hold_out functions in that it
this does not do any padding or max_lengthing of things. It feeds into that because we can then
compute some aggregate values for the entire corpus.
"""
return concatenate_datasets([train_set, validation_set, hold_out_set]).map(
lambda x: tokenizer(x["input_text"], truncation=True),
batched=True,
remove_columns=["input_text", "output_text"],
)
def input_lengths(tokenized_inputs: DatasetType) -> list[int]:
"""The lengths of the input sequences."""
return [len(x) for x in tokenized_inputs["input_ids"]]
def max_source_lengths(input_lengths: list[int]) -> int:
"""The 95th percentile of the input lengths."""
return int(np.percentile(input_lengths, 95))
def tokenized_targets(
train_set: Dataset,
validation_set: Dataset,
hold_out_set: Dataset,
tokenizer: PreTrainedTokenizerBase,
) -> DatasetType:
"""Tokenizes the outputs, i.e. target responses, from all the datasets and creates a single data set with them.
This is different from the tokenized_train, tokenized_validation, and tokenized_hold_out functions in that it
this does not do any padding or max_lengthing of things. It feeds into that because we can then
compute some aggregate values for the entire corpus.
"""
return concatenate_datasets([train_set, validation_set, hold_out_set]).map(
lambda x: tokenizer(x["output_text"], truncation=True),
batched=True,
remove_columns=["input_text", "output_text"],
)
def target_lengths(tokenized_targets: DatasetType) -> list[int]:
"""The lengths of the target sequences."""
return [len(x) for x in tokenized_targets["input_ids"]]
def max_target_lengths(target_lengths: list[int]) -> int:
"""The 95th percentile of the target lengths."""
return int(np.percentile(target_lengths, 95))
def _preprocess_function(
sample,
max_source_lengths: int,
max_target_lengths: int,
tokenizer: PreTrainedTokenizerBase,
padding="max_length",
):
"""Helper function to preprocess the data."""
# add prefix to the input for t5
inputs = [item for item in sample["input_text"]]
# tokenize inputs
model_inputs = tokenizer(
inputs, max_length=max_source_lengths, padding=padding, truncation=True
)
# Tokenize targets with the `text_target` keyword argument
labels = tokenizer(
text_target=sample["output_text"],
max_length=max_target_lengths,
padding=padding,
truncation=True,
)
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
# padding in the loss.
if padding == "max_length":
labels["input_ids"] = [
[(token if token != tokenizer.pad_token_id else -100) for token in label]
for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
def tokenized_train(
train_set: Dataset,
max_source_lengths: int,
max_target_lengths: int,
tokenizer: PreTrainedTokenizerBase,
) -> Dataset:
"""Tokenizes the training set."""
return train_set.map(
partial(
_preprocess_function,
max_source_lengths=max_source_lengths,
max_target_lengths=max_target_lengths,
tokenizer=tokenizer,
),
batched=True,
remove_columns=["input_text", "output_text"],
)
def tokenized_validation(
validation_set: Dataset,
max_source_lengths: int,
max_target_lengths: int,
tokenizer: PreTrainedTokenizerBase,
) -> Dataset:
"""Tokenizes the validation set."""
return validation_set.map(
partial(
_preprocess_function,
max_source_lengths=max_source_lengths,
max_target_lengths=max_target_lengths,
tokenizer=tokenizer,
),
batched=True,
remove_columns=["input_text", "output_text"],
)
def tokenized_hold_out(
hold_out_set: Dataset,
max_source_lengths: int,
max_target_lengths: int,
tokenizer: PreTrainedTokenizerBase,
) -> Dataset:
"""Tokenizes the inference set."""
return hold_out_set.map(
partial(
_preprocess_function,
max_source_lengths=max_source_lengths,
max_target_lengths=max_target_lengths,
tokenizer=tokenizer,
),
batched=True,
remove_columns=["input_text", "output_text"],
)
def saved_datasets(
tokenized_train: Dataset,
tokenized_validation: Dataset,
tokenized_hold_out: Dataset,
) -> dict:
"""Function to save tokenized datasets using the datasets library."""
tokenized_train.save_to_disk("data/train")
tokenized_validation.save_to_disk("data/validation")
tokenized_hold_out.save_to_disk("data/inference")
return {
"tokenized_train": "data/train",
"tokenized_validation": "data/validation",
"tokenized_hold_out": "data/inference",
}
def lora_config() -> LoraConfig:
"""Define the LoRA Config"""
return LoraConfig(
r=16,
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.2,
bias="none",
task_type=TaskType.SEQ_2_SEQ_LM,
)
def device() -> torch.device:
"""The device to use for training & inference.
Defaults to CPU.
Note: on mac the underlying huggingface library will try to use MPS,
so it might not work to change the value here.
:return: the device to use.
"""
return torch.device("cuda" if torch.cuda.is_available() else "cpu")
def base_model(
lora_config: LoraConfig,
device: torch.device,
model_id: str,
load_in_8bit: bool = False,
) -> torch.nn.Module:
"""Returns the base LoraModel to use for fine tuning.
Note, it returns the model on the device specified by the device parameter.
:param lora_config: the lora config to use.
:param device: the device to use.
:param load_in_8bit: whether to load the model in 8bit.
:param model_id: the model id to use.
:return: the model - unfit.
"""
model = AutoModelForSeq2SeqLM.from_pretrained(
model_id,
# device_map="auto",
load_in_8bit=load_in_8bit,
)
if load_in_8bit:
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_config)
# model.print_trainable_parameters()
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
model = model.to(device)
return model
def data_collator(
tokenizer: PreTrainedTokenizerBase,
base_model: torch.nn.Module,
label_pad_token_id: int = -100,
pad_to_multiple_of: int = 8,
) -> DataCollatorForSeq2Seq:
"""Defines the data collator to use.
:param tokenizer: the tokenizer to use.
:param base_model: the base model to use.
:param label_pad_token_id: defaults to -100 because we want to ignore tokenizer pad token in the loss.
:param pad_to_multiple_of: pads to multiple of 8 by default.
:return:
"""
return DataCollatorForSeq2Seq(
tokenizer,
model=base_model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=pad_to_multiple_of,
)
def peft_model_id(model_id: str) -> str:
"""The ID we're running everything under here."""
return f"hamilton-{model_id.replace('/', '-')}-peft"
def training_args(
peft_model_id: str,
per_device_eval_batch_size: int = 8,
per_device_train_batch_size: int = 8,
gradient_accumulation_steps: int = 1,
num_train_epochs: int = 2,
) -> Seq2SeqTrainingArguments:
"""Constructs the arguments to use for fine-tuning.
:param peft_model_id: The ID we're running everything under here.
:param per_device_eval_batch_size: The batch size for evaluation. This is the number of samples that will be fed to
the model at once during evaluation.
:param per_device_train_batch_size: The batch size for training. This is the number of samples that will be fed to
the model at once during training.
:param gradient_accumulation_steps: The number of steps to accumulate gradients before performing an optimization
step. This can be useful when training on multiple GPUs to effectively increase the batch size.
:param num_train_epochs: The number of epochs to train the model. An epoch is one pass through the entire training
dataset.
:return: Seq2SeqTrainingArguments object, the arguments for training such as batch size, learning rate, etc.
"""
training_args = Seq2SeqTrainingArguments(
do_train=True,
do_eval=True,
evaluation_strategy="epoch",
logging_strategy="epoch",
save_strategy="epoch",
per_device_eval_batch_size=per_device_eval_batch_size,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
output_dir=peft_model_id,
auto_find_batch_size=True,
learning_rate=1e-3, # higher learning rate
num_train_epochs=num_train_epochs,
logging_dir=f"{peft_model_id}/logs",
report_to=["none"],
# use_mps_device=False # if running on mac try uncommenting this.
)
return training_args
def trainer(
base_model: torch.nn.Module,
training_args: Seq2SeqTrainingArguments,
data_collator: DataCollatorForSeq2Seq,
tokenized_train: Dataset,
tokenized_validation: Dataset,
) -> Seq2SeqTrainer:
"""Constructs a Seq2SeqTrainer for fine-tuning.
:param base_model: torch.nn.Module object, the base model to be fine-tuned.
:param training_args: Seq2SeqTrainingArguments object, the arguments for training such as batch size, learning rate,
etc.
:param data_collator: DataCollatorForSeq2Seq object, the data collator that will be used to form batches for
training.
:param tokenized_train: Dataset object, the training set that has been tokenized.
:param tokenized_validation: Dataset object, the validation set that has been tokenized.
:return: Seq2SeqTrainer object, the trainer that will be used for fine-tuning.
"""
trainer = Seq2SeqTrainer(
model=base_model,
args=training_args,
data_collator=data_collator,
train_dataset=tokenized_train,
eval_dataset=tokenized_validation,
)
return trainer
@extract_fields(
{
"fit_trainer": Seq2SeqTrainer,
"fit_trainer_eval_metrics": dict,
"finetuned_model": torch.nn.Module,
}
)
@config.when(start="base")
def fitted_and_evaluated_trainer(trainer: Seq2SeqTrainer, device: torch.device) -> dict:
"""Fits and evaluates the trainer.
:param trainer: the trainer to use.
:param device: device to place the device on to.
:return: dictionary with the trainer, the evaluation metrics, and the fine-tuned model.
"""
trainer.train()
eval_metrics = trainer.evaluate()
finetuned_model = trainer.model
finetuned_model.eval()
finetuned_model.to(device)
return {
"fit_trainer": trainer,
"fit_trainer_eval_metrics": eval_metrics,
"finetuned_model": finetuned_model,
}
def save_best_models(
tokenizer: PreTrainedTokenizerBase, peft_model_id: str, trainer: Seq2SeqTrainer
) -> dict:
"""Function to save the tokenizer and models -- fine-tuned and base."""
trainer.model.save_pretrained(peft_model_id) # fine tuned
tokenizer.save_pretrained(peft_model_id)
trainer.model.base_model.save_pretrained(peft_model_id)
return {
"name": "save_best_models",
"status": "success",
"peft_model_id": peft_model_id,
}
def peft_config(peft_model_id: str) -> PeftConfig:
"""Gets config for the peft model."""
return PeftConfig.from_pretrained(peft_model_id)
@config.when(start="presaved")
def finetuned_model__presaved(
peft_config: PeftConfig,
peft_model_id: str,
device: torch.device,
) -> PeftModel:
"""Returns a presaved model and puts it on the device specified."""
# change the following device maps if you want to run on GPU
model = AutoModelForSeq2SeqLM.from_pretrained(
peft_config.base_model_name_or_path, device_map={"": "cpu"}
) # {"":0}
model = PeftModel.from_pretrained(model, peft_model_id, device_map={"": "cpu"}) # {"":0}
model.eval()
model.to(device)
return model
@config.when(start="presaved")
def fit_tokenizer__presaved(peft_config: PeftConfig) -> PreTrainedTokenizerBase:
"""Returns presaved tokenizer."""
tokenizer = AutoTokenizer.from_pretrained(peft_config.base_model_name_or_path)
return tokenizer
def metric() -> evaluate.EvaluationModule:
"""Return the metric to use."""
return evaluate.load("rouge")
def _evaluate_peft_model(sample, model, tokenizer, device, max_target_length=512) -> tuple:
"""Helper function to evaluate the model on a sample.
:param sample: The sample on which the model is to be evaluated. This is typically a single instance from the
dataset.
:param model: The model to be used for evaluation. This is typically the fine-tuned model.
:param tokenizer: The tokenizer that was used during the preprocessing of the data.
This will be used to decode the model's predictions from token ids back to text.
:param device: The device where the computations will be performed. This is typically a CPU or a specific GPU.
:param max_target_length: The maximum length of the target sequence. If the predicted sequence is longer than this,
it will be truncated to this length.
:return: A tuple containing the prediction and the ground truth label.
"""
# generate summary
# outputs = model.generate(
# input_ids=sample["input_ids"].unsqueeze(0).cuda(),
# do_sample=True, top_p=0.9, max_new_tokens=max_target_length)
outputs = model.generate(
input_ids=sample["input_ids"].unsqueeze(0).to(device),
do_sample=True,
top_p=0.9,
max_new_tokens=max_target_length,
)
prediction = tokenizer.decode(outputs[0].detach().cpu().numpy(), skip_special_tokens=True)
# decode eval sample
# Replace -100 in the labels as we can't decode them.
labels = np.where(sample["labels"] != -100, sample["labels"], tokenizer.pad_token_id)
# Some simple post-processing
labels = tokenizer.decode(labels, skip_special_tokens=True)
return prediction, labels
# run predictions
# this can take ~45 minutes
@extract_fields({"validation_predictions": list, "validation_references": list})
def finetuned_model_on_validation_set(
tokenized_validation: Dataset,
finetuned_model: torch.nn.Module,
tokenizer: PreTrainedTokenizerBase,
device: torch.device,
) -> dict[str, list]:
"""
Evaluates the fine-tuned model on the validation set.
This function iterates over the validation set and generates predictions for each sample.
The predictions and the ground truth labels are then returned as a dictionary.
Note: If you run this on a large model this can take a while.
:param tokenized_validation: Dataset object, the validation set that has been tokenized.
This is the data that the model has seen during training and will be used for testing the model's performance.
:param finetuned_model: torch.nn.Module object, the fine-tuned model that will be used to generate predictions
on the validation set. This model has been trained on the training set.
:param tokenizer: PreTrainedTokenizerBase object, the tokenizer that was used during the preprocessing
of the data. This will be used to decode the model's predictions from token ids back to text.
:param device: torch.device object, the device where the computations will be performed.
This is typically a CPU or a specific GPU.
:return: Dictionary containing two lists - 'validation_predictions' and 'validation_references'.
'validation_predictions' is a list of model predictions for each sample in the validation set.
'validation_references' is a list of ground truth labels for each sample in the validation set.
"""
predictions, references = [], []
with torch.inference_mode():
for sample in tqdm(tokenized_validation.with_format("torch")):
prediction, labels = _evaluate_peft_model(
sample=sample,
model=finetuned_model,
tokenizer=tokenizer,
max_target_length=512,
device=device,
)
predictions.append(prediction)
references.append(labels)
print("#" * 10)
print(f"prediction = {prediction}, labels = {labels}")
return {"validation_predictions": predictions, "validation_references": references}
# compute metric
def validation_set_metrics(
validation_predictions: list,
validation_references: list,
metric: evaluate.EvaluationModule,
) -> dict:
"""Computes the Rouge metric on the validation set.
:param validation_predictions: List of model predictions for each sample in the validation set.
:param validation_references: List of ground truth labels for each sample in the validation set.
:param metric: EvaluationModule object, the metric used to evaluate the model's performance.
In this case, it's Rouge.
:return: Dictionary containing the Rouge scores for the model's performance on the validation set.
"""
rogue = metric.compute(
predictions=validation_predictions,
references=validation_references,
use_stemmer=True,
)
eval_rouge_scores = {
"rogue1": rogue["rouge1"] * 100,
"rouge2": rogue["rouge2"] * 100,
"rougeL": rogue["rougeL"] * 100,
"rougeLsum": rogue["rougeLsum"] * 100,
}
return eval_rouge_scores
def training_and_validation_set_metrics(
validation_set_metrics: dict, fit_trainer_eval_metrics: dict
) -> dict:
"""Combines the training and validation set metrics."""
return {**fit_trainer_eval_metrics, **validation_set_metrics}
def hold_out_set_predictions(
tokenized_hold_out: Dataset,
finetuned_model: torch.nn.Module,
tokenizer: PreTrainedTokenizerBase,
device: torch.device,
) -> list[tuple[str, str]]:
"""Runs model on the inference set.
:param tokenized_hold_out: Dataset object, the hold-out set that has been tokenized.This is the data that the
model has not seen during training or validation and will be used for testing the model's performance.
:param finetuned_model: torch.nn.Module object, the fine-tuned model that will be used to generate predictions
on the hold-out set.
This model has been trained on the training set and validated on the validation set.
:param tokenizer: PreTrainedTokenizerBase object, the tokenizer that was used during the preprocessing
of the data. This will be used to decode the model's predictions from token ids back to text.
:param device: torch.device object, the device where the computations will be performed.
This is typically a CPU or a specific GPU.
:return: generate responses for the inference set
"""
predictions = []
questions = []
with torch.inference_mode():
for sample in tokenized_hold_out.with_format("torch", device=device):
max_target_length = 512
outputs = finetuned_model.generate(
input_ids=sample["input_ids"].unsqueeze(0).cpu(),
do_sample=True,
top_p=0.9,
max_new_tokens=max_target_length,
)
prediction = tokenizer.decode(
outputs[0].detach().cpu().numpy(), skip_special_tokens=True
)
predictions.append(prediction)
questions.append(tokenizer.decode(sample["input_ids"], skip_special_tokens=True))
return list(zip(questions, predictions))
if __name__ == "__main__":
import os
import time
import __init__ as fine_tuning
from hamilton import driver
from hamilton.plugins import h_tqdm
# torch.set_default_device("cpu")
start_time = time.time()
h_adapters = [
h_tqdm.ProgressBar("fine-tuning"),
]
try:
from dagworks import adapters
tracker = adapters.DAGWorksTracker(
project_id=int(os.environ["DAGWORKS_PROJECT_ID"]),
api_key=os.environ["DAGWORKS_API_KEY"],
username=os.environ["DAGWORKS_USERNAME"],
dag_name="fine_tuning",
tags={"environment": "DOCKER", "team": "MY_TEAM", "version": "0.0.1"},
)
h_adapters.append(tracker)
except ImportError:
pass
except KeyError:
pass
dr = (
driver.Builder()
.with_config({"start": "base"})
.with_modules(fine_tuning)
.with_adapters(*h_adapters)
.build()
)
dr.display_all_functions("dag.png", orient="TB", deduplicate_inputs=True)
result = dr.execute(
[
"save_best_models",
"hold_out_set_predictions",
"training_and_validation_set_metrics",
"finetuned_model_on_validation_set",
],
inputs={
"model_id": "google/flan-t5-small",
"data_path": "example-support-dataset.json",
"input_text_key": "question",
"output_text_key": "gpt4_replies_target",
},
)
import pprint
pprint.pprint(result)
print("--- %s seconds ---" % (time.time() - start_time))
Requirements
absl-py
datasets
evaluate
numpy
pandas
peft
rouge-score
scikit-learn
sf-hamilton
torch
tqdm
transformers
# dagworks-sdk -- use if you want to track your runs with DAGWorks